Производительность вычислительного кластера НИВЦ МГУ
Здесь собраны данные по производительности 36-процессорного кластера SCI и 40-процессорного кластера SKY, полученные в 2001 году. В настоящее время кластер SKY является частью кластера AQUA. Доступны также более ранние данные по производительности 24-процессорного фрагмента кластера SCI, собранного в 2000 году.
Суммарная пиковая производительность кластера SCI - 18 Гфлопс (36 процессоров, каждый с пиковой производительностью 500 Мфлопс), кластера SKY - 34 Гфлопс. Производительность на реальных приложениях обусловлена, в первую очередь, параллельными свойствами самих приложений, а также производительностью коммуникационной среды.
Термин SCI здесь используется как название высокоскоростной сети и как название одного из двух кластеров.
Содержание
Производительность коммуникационной среды
Латентность (время задержки сообщений) в рамках MPI поверх SCI составляет примерно 5.8 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 81 Мбайт/сек. Двунаправленные пересылки улучшают суммарную скорость обмена при сообщениях длиной до 256 Кбайт. На следующем рисунке представлена зависимость скорости пересылок от размера сообщения (от 1K до 16 Мбайт).
![]()
Рис.1. Скорость пересылок в рамках MPI на кластере SCI.
Для сравнения: в рамках MPI поверх Fast Ethernet скорость пересылок составляет до 10 Мбайт/сек, а время латентности - около 150 микросекунд. При обменах в рамках одного SMP-узла достигается латентность около 2.5 микросекунд и скорость обменов порядка 100 Мбайт/сек для сообщений среднего размера (до 256 Кбайт).
![]()
Рис.2. Скорость пересылок в рамках MPI на кластерах SCI и SKY -
между узлами и в рамках SMP-узла.
![]()
Рис.3. Время на пересылку небольших сообщений
в рамках MPI на кластерах SCI и SKY - между узлами и в рамках SMP-узла.
Более подробную информацию об используемых здесь тестах производительности MPI можно найти по адресу http://parallel.ru/testmpi/.
Тест LINPACK
Тест LINPACK представляет собой решение больших систем линейных алгебраических уравнений методом LU-разложения. Результаты теста используются при составлении знаменитого списка Top500. Параллельная реализация LINPACK основана на библиотеке SCALAPACK.
Производительность определяется как количество "содержательных" операций с плавающей точкой в расчете на 1 секунду, и выражается в MFLOPS. Число выполненных операций с плавающей точкой оценивается по формуле 2n3/3 + 2n2 (здесь n - размерность матрицы).
При решении системы уравнений с матрицей 44000x44000 на 36 процессорах кластера SCI была получена производительность в 10 Гфлопс. Максимальная производительность кластера SKY составила примерно 13 Гфлопс.
Более подробные данные по производительности на LINPACK (с различным размером задачи и различным числом процессоров на двух кластерах) приведены на следующих графиках и диаграммах.
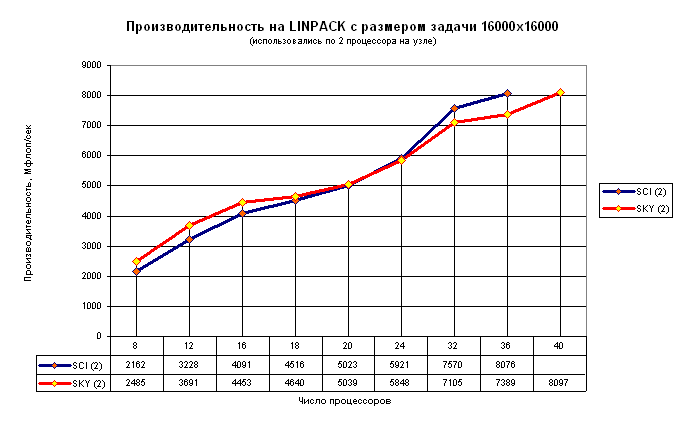
Рис.4. Производительность кластеров SCI и SKY на LINPACK с размером
задачи 16000x16000 при различном числе используемых процессоров.
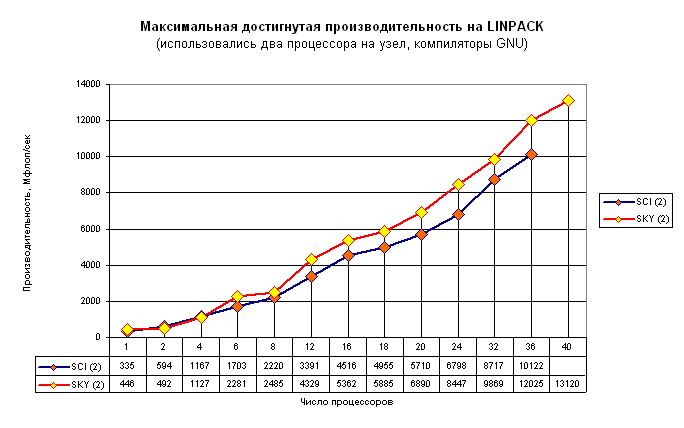
Рис.5. Производительность кластеров SCI и SKY на LINPACK
при различном числе используемых процессоров - для каждого числа
процессоров N подбирается максимально достигнутая производительность.
Для кластера SСI было проведено сравнение производительности при использовании сети SCI (ScaMPI) и Fast Ethernet (MPICH). Эти данные представлены на следующих двух рисунках.
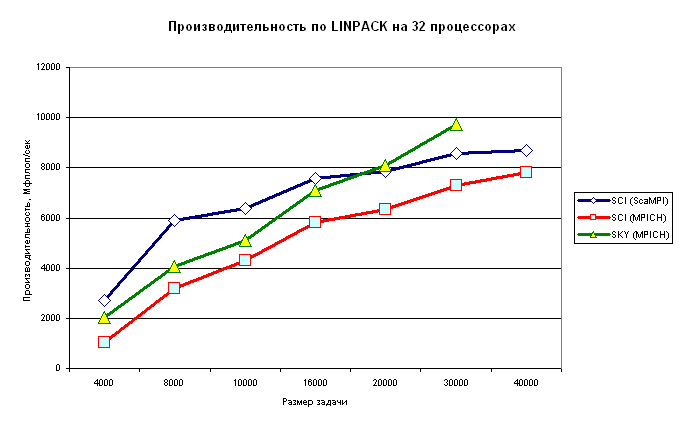
Рис.6. Производительность кластеров SCI и SKY на LINPACK -
32 процессора, меняется размер задачи.
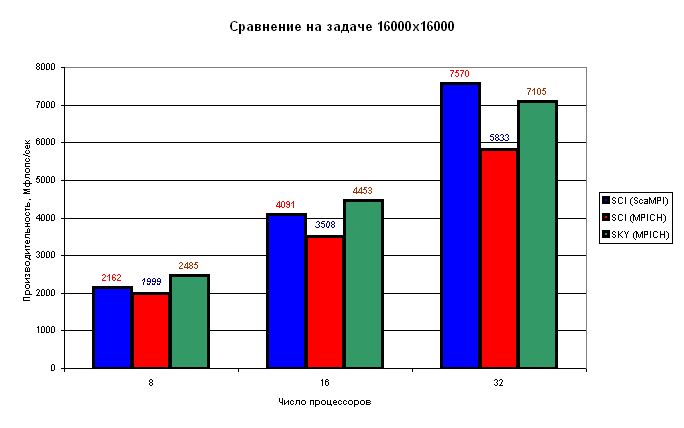
Рис.6. Производительность кластеров SCI и SKY на LINPACK -
размер задачи 16000x16000, различое число процессоров.
Таким образом, при использовании высокоскоростной сети SCI достигается выигрыш по сравнению с 100-Мбитной сетью до 29% на тех же самых процессорах (500 МГц) и до 6% на более мощных процессорах (850 МГц) Следует отметить, что тест LINPACK не слишком требователен к производительности пересылок. Для других приложений сеть SCI дает более значительный выигрыш.