Производительность кластера
На данной страничке собрана информация по производительности 24-процессорного фрагмента кластера, полученные в 2000 году.
Содержание
- Производительность коммуникационной среды.
- Производительность на тесте LINPACK.
- Производительность на тестах NPB.
Производительность коммуникационной среды
Латентность (время задержки сообщений) в рамках MPI поверх SCI составляет примерно 5.6 мксек, а максимальная достигнутая скорость однонаправленных пересылок составляет 80 MB/sec. Для сравнения: в рамках MPI поверх Fast Ethernet скорость пересылок составляет 7-10 MB/sec, а латентности - около 150-200 мксек. На следующем рисунке представлена зависимость скорости пересылок от размера сообщения (от 1K до 8MB).
![]()
Рис.1a. Скорость пересылок в рамках MPI.
Сравнение SCI и Fast Ethernet
Для проведения сравнительных тестов дополнительно установлен пакет MPICH 1.2.0, который обеспечивает реализацию MPI поверх Fast Ethernet. Латентность при использовании Fast Ethernet - 158 микросекунд, т.е. в 28 раз больше, чем при использовании сети SCI.
![]()
Рис.1b. Скорость пересылок в рамках MPI поверх SCI и Fast Ethernet, небольшие сообщения.
![]()
Рис.1c. Скорость пересылок в рамках MPI поверх SCI и Fast Ethernet, длинные сообщения.
Более подробную информацию о тестах производительности MPI можно найти по адресу http://parallel.ru/testmpi/.
Тест LINPACK
Тест LINPACK представляет собой решение больших систем линейных алгебраических уравнений методом LU-разложения. Результаты теста используются при составлении знаменитого списка Top500. Параллельная реализация LINPACK основана на библиотеке SCALAPACK.
Производительность определяется как количество "содержательных" операций с плавающей точкой в расчете на 1 секунду, и выражается в MFLOPS. Число выполненных операций с плавающей точкой оценивается по формуле 2n3/3 + 2n2 (здесь n - размерность матриы).
При решении системы уравнений с матрицей 44000x44000 на 36 процессорах кластера была получена производительность в 9.7 Гфлопс.
При решении системы с матрицей 16000x16000 на 24 процессорах кластера была получена производительность в 5.8 Гфлопс. Более подробные данные по производительности на LINPACK с различным размером задачи и различным числом процессоров приведены на следующих графиках и диаграммах.
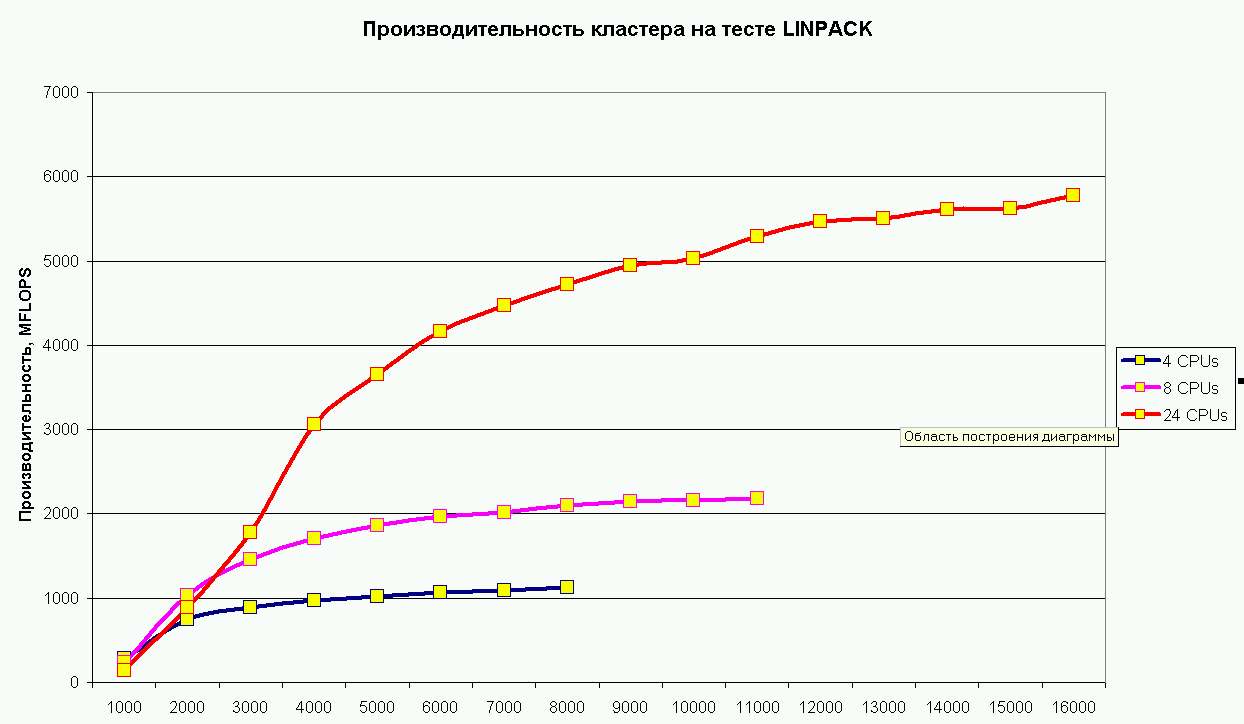
Рис.2. Производительность кластера на LINPACK с различными
размерами матрицы - 4, 8, 24 процессора.
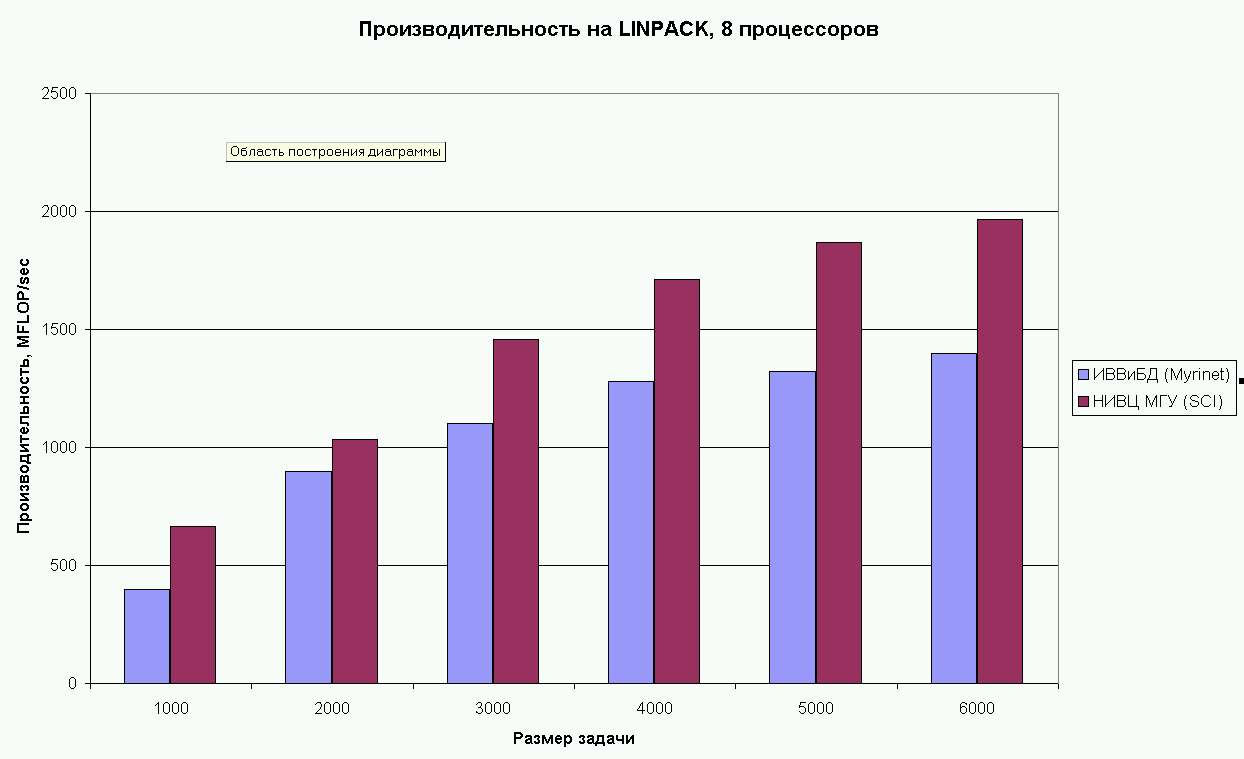
Рис.3. Производительность на LINPACK кластеров НИВЦ МГУ
и "Паритет" (ИВВиБД) с различными размерами матрицы -
8 процессоров.
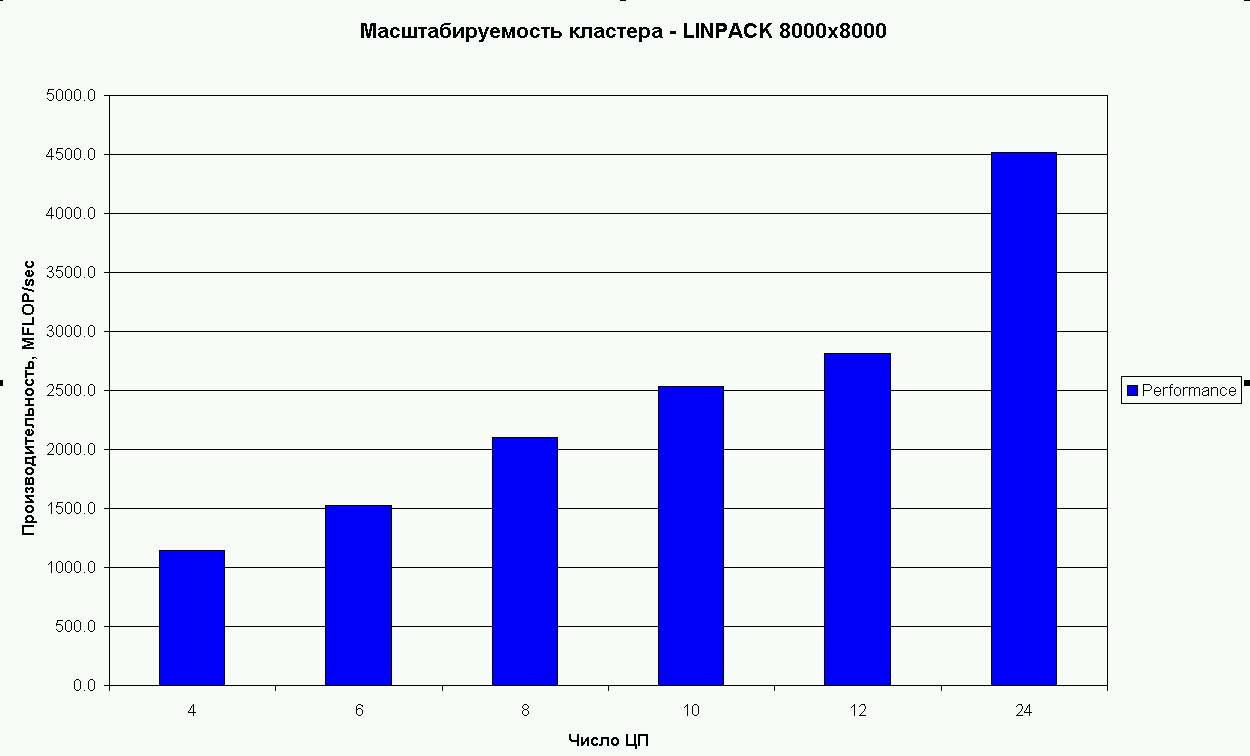
Рис.4. Масштабируемость кластера на LINPACK с размером
матрицы 8000x8000 - 4, 6, 8, 12, 10, 24 процессора.
Тесты пакета NPB (NAS Parallel Benchmarks)
Пакет NAS Parallel Benchmarks содержит восемь задач, пять из которых (EP, FT, MG, IS, CG) яаляются задачами-ядрами (kernel benchmarks), а три (LU,SP,BT) - моделями прикладных задач (application benchmarks). Задачи были выбраны после оценки множества больших прикладных программ вычислительной гидродинамики, решаемых в NASA.
Задачи пакета NPB содержат значительно больше вычислений, чем использовавшиеся ранее бенчмарки, например такие, как Livermore Loops или LINPACK, поэтому они более приемлемы для оценки параллельных машин. С другой стороны, эти задачи относительно просты, что позволяет ставить эти задачи на новых вычислительных системах без значительных усилий и задержек.
В следующих таблицах приведены результаты запуска тестов NPB 2.3 c параметрами класса "А" на 4, 8(9) и 16 процессорах кластера в сравнении с некоторыми другими параллельными системами. Везде указаны времена выполнения тестов в секундах.
4 процессора
| LU | SP | BT | EP | MG | FT | IS | CG | |
|
Кластер ИВВиБД - Pentium II/450, Fast Ethernet |
611.6 | 987.4 | 1106.8 | 93.5 | 48.7 | - | 32.1 | 33.5 |
|
Кластер ИВВиБД - Pentium II/450, Myrinet |
593.9 | 824.3 | 1019.5 | 94.3 | 43.8 | - | 6.7 | 21.2 |
|
Cray T3E 900 |
441.1 | 493.8 | 742.4 | 51.5 | 12.4 | 42.1 | 6.5 | 17.4 |
|
Cray T3E 1200 |
384.6 | 434.1 | 636.0 | 39.4 | 11.0 | 37.8 | 5.8 | 15.5 |
|
НИВЦ МГУ |
361.55 | 435.16 | 606.14 | 97.71 | 22.16 | 42.54 | 5.24 | 11.67 |
8 процессоров системы
| LU | SP (9) | BT (9) | EP | MG | FT | IS | CG | |
|
Origin 2000/195 MHz |
144.30 | 142.00 | 314.00 | 15.40 | 7.60 | 23.10 | 4.40 | 4.40 |
|
Cray T3E 900 |
224.60 | 233.80 | 331.00 | 25.80 | 5.40 | 21.60 | 3.80 | 6.20 |
|
Cray T3E 1200 |
195.30 | 204.40 | 284.60 | 19.70 | 4.80 | 19.20 | 3.20 | 5.70 |
|
НИВЦ МГУ |
165.70 | 284.74 | 207.66 | - | 9.73 | 21.24 | 2.86 | 6.32 |
Примечание. Для тестов SP и BT необходимо число процессоров, равное квадрату целого числа, поэтому взяты 9 процессоров.
16 процессоров
| LU | SP | BT | EP | MG | FT | IS | CG | |
|
Origin 2000/195 MHz |
67.40 | 79.10 | 161.40 | 7.70 | 4.00 | 11.80 | 2.70 | 2.60 |
|
Cray T3E 900 |
116.70 | 132.20 | 191.40 | 12.90 | 3.10 | 11.00 | 2.40 | 5.00 |
|
Cray T3E 1200 |
101.00 | 115.30 | 164.30 | 9.80 | 2.70 | 9.80 | 2.20 | 4.80 |
|
НИВЦ МГУ |
84.49 | 220.79 | 146.48 | - | 7.00 | 13.30 | 2.28 | 4.97 |
Смотрите также:
- ИВВиБД: Результаты тестирования кластера ПАРИТЕТ.
- Тесты производительности компьютеров и системного ПО.
- Frequently Asked Questions on the Linpack Benchmark and Top500.
© Лаборатория Параллельных информационных технологий НИВЦ МГУ