Производительность кластера SCI на тесте Linpack
Документ подготовлен 7 июля 2004 г.
Здесь собраны данные по производительности 32-процессорного кластера SCI на процессорах Pentium III, полученные в апреле-мае 2004 года. Результаты предыдущих тестов можно найти здесь.
Содержание
- Конфигурация кластера SCI.
- Использованное программное обеспечение.
- Производительность процессора.
- Производительность кластера.
Конфигурация кластера SCI
| Характеристика | Кластер SCI |
|---|---|
| Процессор | Pentium III (Katmai) |
| Тактовая частота процессора | 500 (550) МГц |
| Кэш-память второго уровня (на каждом процессоре) | 512 Кбайт |
| Процессоров на узле | 2 |
| Объем памяти на узле | 1 Гбайт (PC-100) |
| Чипсет | Intel 440BX |
| Узлов в кластере | 16 |
| Частота системной шины (FSB) | 100 МГц |
| Адаптеры SCI | D311/D312 (на шине PCI-32/33 МГц) |
| Топология сети SCI | 2D-тор 4x4 |
| Коммуникационное ПО | SSP 2.1 |
Использованное программное обеспечение
Была использована общедоступная параллельная реализация теста LINPACK - HPL 1.0a, которая реализована на языке Си, причем обмены между процессорами выполняются через процедуры интерфейса MPI, а вычисления на каждом процессоре - с помощью вызовов процедур BLAS. В наших экспериментах на кластере SCI в качестве BLAS использовалась библиотека ATLAS 3.6.0, откомпилированная нами с использованием компилятора Intel compiler 7.1, а в качестве реализации MPI для сети SCI - библиотека ScaMPI компании Scali.
Производительность процессора
На тесте LINPACK с максимально возможным размером матрицы (10000x10000) была получена производительность одного процессора Pentium III/0.5 ГГц, равная 0.37 Gflop/s (74% пиковой производительности).
Производительность кластера
На кластере SCI была получена максимальная производительность равная 10.68 Gflop/s (66.8% пиковой производительности) при решении задачи размером 41000x41000 на всех 32 процессорах. Это примерно в 28.9 раз лучше производительности на одном процессоре Pentium III/0.5 ГГц (на задаче размером 10000x10000).
Все результаты тестирования кластера SCI на тесте Linpack приведены на следующем графике. Здесь самый верхний график ("пик") показывает пиковую производительность кластера, второй ("идеал") - производительность при идеальной масштабируемости, последующие графики - реальную производительность кластера при соответствующих размерах задачи.
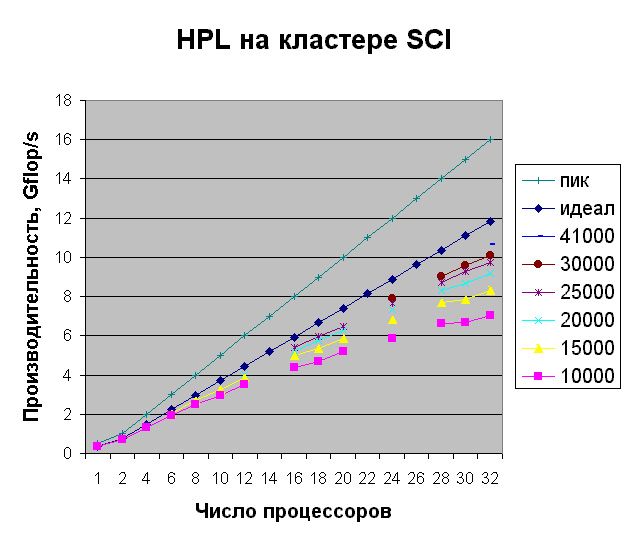
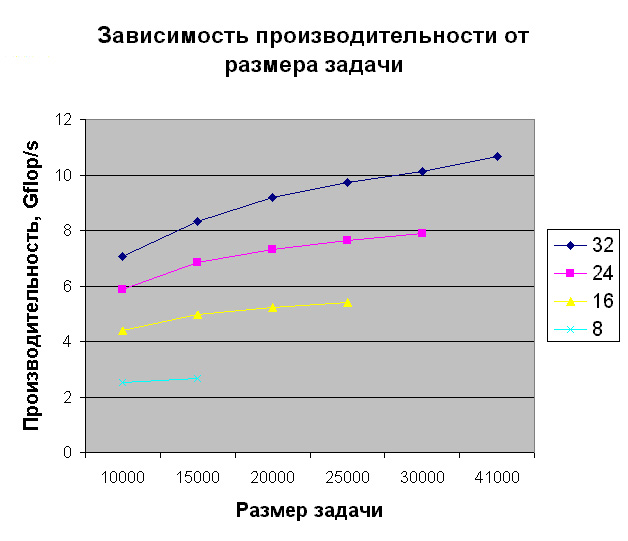
Как изменяется производительность при увеличении размера задачи?
Чему равна эффективность использования кластера?
Графики эффективности приводятся для задачи размером 10000x10000 (это максимальный размер, который попадает в память 1 узла) и для размеров задач, на которых получены максимальные значения.
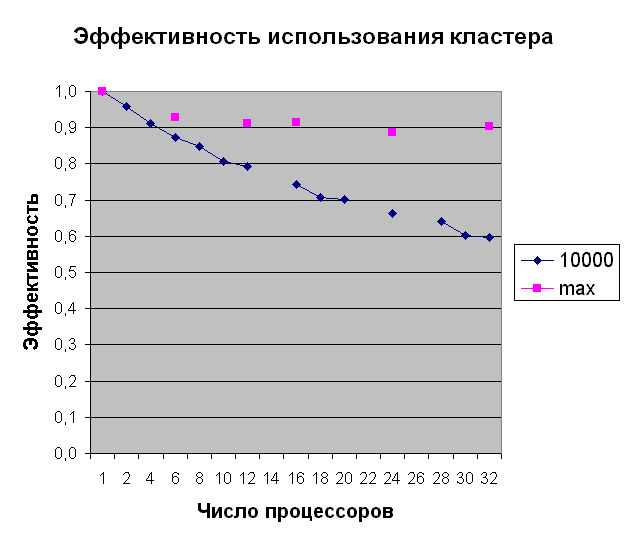
Из этого графика видно, что при фиксированном размере задачи эффективность падает c увеличением числа процессоров от 1 до 32. Если же одновременно увеличивать и размер задачи, то эффективность использования кластера удается существенно увеличить и удерживать на уровне примерно 90%.