7.3.1. Intercommunicator Collective Operations



Up: Extended Collective Operations Next: Operations that Move Data Previous: Extended Collective Operations
In the MPI-1 standard (Section 4.2), collective operations only apply to intracommunicators; however, most MPI collective operations can be generalized to intercommunicators. To understand how MPI can be extended, we can view most MPI intracommunicator collective operations as fitting one of the following categories (see, for instance, [20]):
- All-To-All
-
All processes contribute to the result. All processes
receive the result.
- MPI_Allgather, MPI_Allgatherv
- MPI_Alltoall, MPI_Alltoallv
- MPI_Allreduce, MPI_Reduce_scatter
- All-To-One
-
All processes contribute to the result. One process
receives the result.
- MPI_Gather, MPI_Gatherv
- MPI_Reduce
- One-To-All
-
One process contributes to the result. All processes
receive the result.
- MPI_Bcast
- MPI_Scatter, MPI_Scatterv
- Other
-
Collective operations that do not fit into one of the above
categories.
- MPI_Scan
- MPI_Barrier
The MPI_Barrier operation does not fit into this classification since no data is being moved (other than the implicit fact that a barrier has been called). The data movement pattern of MPI_Scan does not fit this taxonomy.
The extension of collective communication from intracommunicators to intercommunicators is best described in terms of the left and right groups. For example, an all-to-all MPI_Allgather operation can be described as collecting data from all members of one group with the result appearing in all members of the other group (see Figure 11 ). As another example, a one-to-all MPI_Bcast operation sends data from one member of one group to all members of the other group. Collective computation operations such as MPI_REDUCE_SCATTER have a similar interpretation (see Figure 12 ). For intracommunicators, these two groups are the same. For intercommunicators, these two groups are distinct. For the all-to-all operations, each such operation is described in two phases, so that it has a symmetric, full-duplex behavior.
For MPI-2, the following intracommunicator collective operations also apply to intercommunicators:
- MPI_BCAST,
- MPI_GATHER, MPI_GATHERV,
- MPI_SCATTER, MPI_SCATTERV,
- MPI_ALLGATHER, MPI_ALLGATHERV,
- MPI_ALLTOALL, MPI_ALLTOALLV, MPI_ALLTOALLW
- MPI_REDUCE, MPI_ALLREDUCE,
- MPI_REDUCE_SCATTER,
- MPI_BARRIER.
( MPI_ALLTOALLW is a new function described in Section Generalized All-to-all Function .)
These functions use exactly the same argument list as their MPI-1 counterparts and also work on intracommunicators, as expected. No new language bindings are consequently needed for Fortran or C. However, in C++, the bindings have been "relaxed"; these member functions have been moved from the MPI::Intercomm class to the MPI::Comm class. But since the collective operations do not make sense on a C++ MPI::Comm (since it is neither an intercommunicator nor an intracommunicator), the functions are all pure virtual. In an MPI-2 implementation, the bindings in this chapter supersede the corresponding bindings for MPI-1.2.
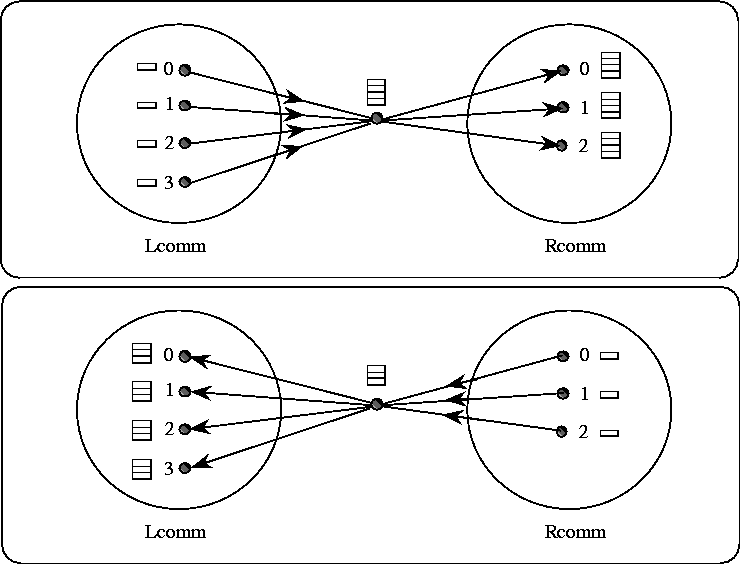
[ ]Intercommunicator allgather. The focus of data to one process is represented, not mandated by the semantics. The two phases do allgathers in both directions.
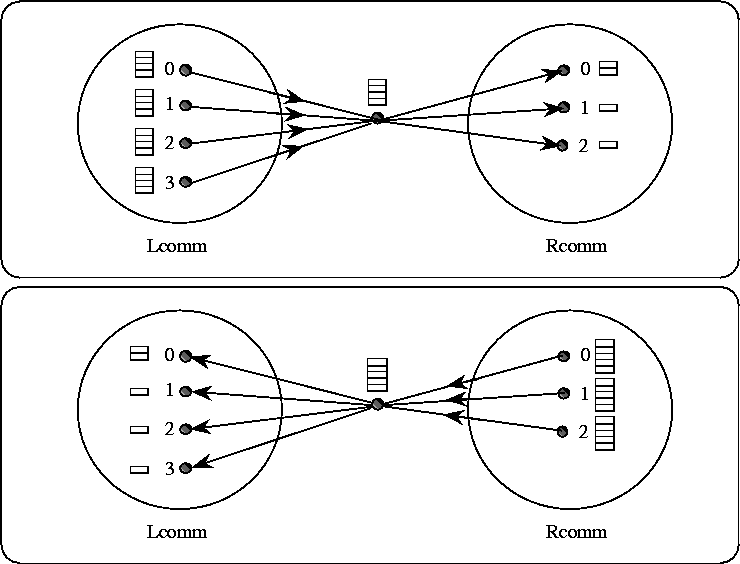
[ ]Intercommunicator reduce-scatter. The focus of data to one process is represented, not mandated by the semantics. The two phases do reduce-scatters in both directions.
Up: Extended Collective Operations Next: Operations that Move Data Previous: Extended Collective Operations
Return to MPI-2 Standard Index
MPI-2.0 of July 18, 1997
HTML Generated on August 11, 1997