Производительность кластера Twin1 на тесте Linpack
Документ подготовлен 12 марта 2007 г.
Здесь собраны данные по производительности 48-процессорного кластера Twin1 на основе двухъядерных процессоров AMD Opteron, полученные в марте 2007 года.
Содержание
- Конфигурация кластера Twin1.
- Использованное программное обеспечение.
- Производительность ядра процессора.
- Производительность кластера.
Конфигурация кластера Twin1
| Характеристика | Кластер Twin1 |
|---|---|
| Процессор | AMD Opteron 285 |
| Тактовая частота процессора | 2600 МГц |
| Процессоров на узле | 2 |
| Объем памяти на узле | 16 Гбайт |
| Узлов в кластере | 24 |
| Коммуникационная сеть | Infiniband 4x |
| Транспортная сеть | Gigabit Ethernet |
| Сервисная сеть | ServNet2 |
Использованное программное обеспечение
Была использована общедоступная параллельная реализация теста LINPACK - HPL 1.0a, которая реализована на языке Си, причем обмены между процессорами выполняются через процедуры интерфейса MPI, а вычисления на каждом процессоре - с помощью вызовов процедур BLAS. В наших экспериментах на кластере Twin1 в качестве BLAS использовалась библиотека Goto BLAS, а в качестве реализации MPI для сети Infiniband - библиотека Qlogic InfiniPath Release 2.0.
Производительность ядра процессора
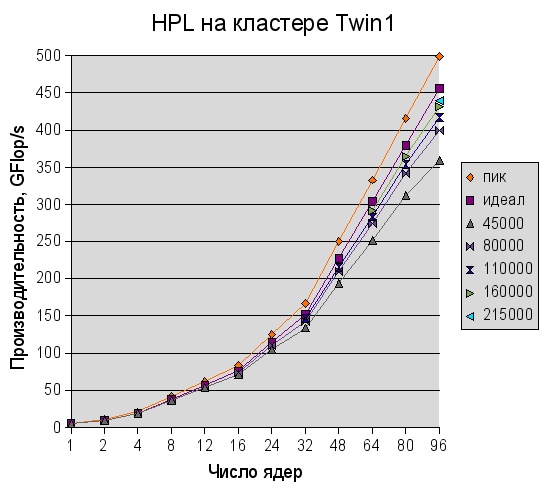
На тесте LINPACK с размером матрицы 45000x45000 была получена производительность одного ядра AMD Opteron/2.6 ГГц, равная 4.8 GFlop/s (92.3% пиковой производительности).
Производительность кластера
На кластере Twin1 была получена максимальная производительность равная 440 GFlop/s (88.1% пиковой производительности) при решении задачи размером 215000x215000 на всех 96 ядрах. Это примерно в 91.7 раз лучше производительности на одном ядре Opteron/2.6 ГГц (на задаче размером 45000x45000).
Результаты тестирования кластера Twin1 на тесте Linpack приведены на следующем графике. Здесь самый верхний график ("пик") показывает пиковую производительность кластера, второй ("идеал") - производительность при идеальной масштабируемости, последующие графики - реальную производительность кластера при соответствующих размерах задачи.
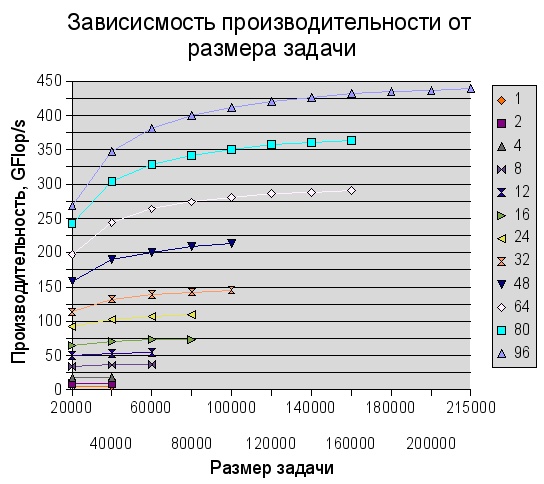
Как изменяется производительность при увеличении размера задачи?
Чему равна эффективность использования кластера?
Графики эффективности приводятся для задачи размером 45000x45000 и для размеров задач, на которых получены максимальные значения.
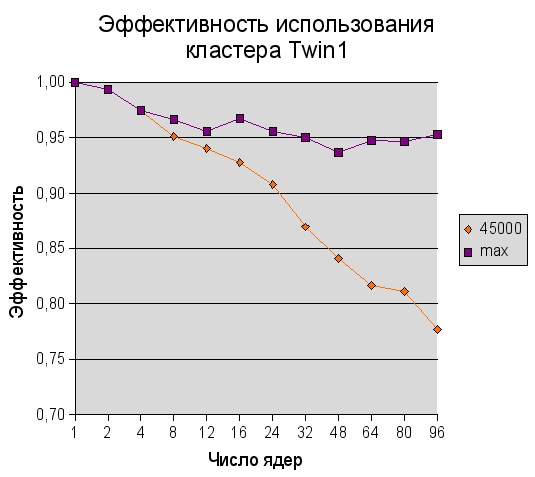
Из этого графика видно, что при фиксированном размере задачи эффективность падает c увеличением числа ядер от 1 до 96. Если же одновременно увеличивать и размер задачи, то эффективность использования кластера удается существенно увеличить и удерживать на уровне примерно 95%.