Тест пропускной способности сети при сложных обменах
Назначение
NETTEST - тест коммуникационной производительности при сложных обменах между несколькими узлами в различных логических топологиях ("звезда", "полный граф", "кольцо"). Тест может использоваться для проверки "выживаемости" сетевого оборудования при пиковых нагрузках и для определения пиковой пропускной способности коммутатора.
Основные понятия
Описанные выше методики тестирования обобщаются для случая нескольких процессов. При этом рассматриваются три логические топологии взаимодействия процессов:
- Звезда (Star), т.е. взаимодействие основного процесса с подчиненными;
- Кольцо (Ring), т.е. взаимодействие каждого процесса со следующим;
- Полный граф (Chaos), т.е. взаимодействие каждого процесса с каждым.
Под логическим каналом будем подразумевать неупорядоченную пару узлов (А,B), которые в данной топологии могут обмениваться сообщениями. Логическая топология полностью определяется множеством задействованных логических каналов.
Для каждой топологии рассматриваются однонаправленные и двунаправленные обмены. По каждому логическому каналу между узлами А и В информация в ходе теста передается в обе стороны: от узла А к узлу B и обратно передается по L байт информации. Однако в случае однонаправленных обменов один из узлов, например В, ждет получения сообщения от А, и только тогда может передавать А свое сообщение. Во втором же случае информация может передаваться в обе стороны одновременно.
Конкретные способы организации пересылок средствами MPI (блокирующие, неблокирующие, и т.д. пересылки) здесь не регламентируются; предполагается, что из всех, соответствующих по семантике данной топологии и способу обменов будет выбран вариант с наименьшими накладными расходами.
Методики тестирования будут описаны ниже.
Пусть для данной топологии задействованы N(P) логических каналов, где
P - число узлов. Тогда суммарный объем передаваемой по сети информации
есть I = 2LN. Пусть узел i имеет Ni(P) логических связей с другими
узлами. Тогда этот узел передает и принимает всего 2LNi(P) байт
информации.
Под локальной пропускной способностью R(local) в каждом тесте понимается
отношение суммарной длины посланных и принятых на данном узле сообщений
к затраченному времени.
Под суммарной пропускной способностью R(total) сети понимается отношение
количества всей переданной по сети информации к затраченному времени.
Под средней пропускной способностью R(avg) одного логического канала
понимается отношение суммарной пропускной способности к количеству задействованных
каналов.
Нас будет в основном интересовать именно эта величина.
Исходя из определений
трех логических топологий, нетрудно выписать следующие выражения для величин
R(local, total, avg) через число узлов P, длину сообщения L и время T,
затраченное на все обмены.
При этом в случае топологии Star рассматривается только основной узел.
Пропускная способность для случая нескольких узлов
| Star | Chaos | Ring | |
| N(P) | P-1 | P(P-1) | P |
| R(local) |
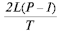
| | 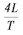 |
| R(total) | | 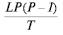 | 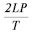 |
| R(avg) | 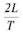 |
||
Методика тестирования для двунаправленных обменов
Рассмотрим сначала двунаправленные обмены в произвольной логической
топологии. Опишем действия каждого из узлов.
Пусть данный узел с номером
i имеет Ni(P) соседей.
Для "общения" c каждым из них выделяется 2 буфера - один для передачи,
другой для приема; каждый из буферов - размером
не менее L байт, где L - интересующий нас размер сообщения. Это замечание
относится ко всем тестам.
- Производится синхронизация с помощью MPI_Barrier.
- Измеряется текущее время t0.
- Инициализируется передача L байт информации всем соседям с помощью неблокирующей операции MPI_Isend.
- Затем инициализируется прием L байт информации от всех соседей с помощью неблокирующей операции MPI_Irecv.
- Все эти неблокирующие операции возвращают набор запросов MPI (MPI_Request). Вызов MPI_Waitall позволяет дождаться завершения всех этих запросов.
- Производится барьерная синхронизация.
- Измеряется текущее время t1.
С целью минимизации погрешности эта процедура повторяется несколько
раз; величина (t1 - t0), усредненная по всем итерациям, и является интересующим
нас временем T. Это замечание также относится ко всем тестам.
Случай однонаправленных обменов удобно рассмотреть для каждой топологии
отдельно.
1) Пусть в логической топологии "Звезда" центральным является
узел 0. Действия центрального узла ничем не отличаются от описанных
в выше.
Его соседями являются все остальные узлы. 2) Топология "Полный граф". 3) Топология "Кольцо" хороша тем, что независимо от общего количества
узлов, каждый узел имеет только двух соседей. Тест реализован в виде нескольких файлов на языке Си.
Основной модуль (оболочка теста)
содержится в файле nettest.c,
необходимые определения и прототипы функций находятся
в заголовочном файле nettest.h.
а в файлах star.c, chaos.c, ring.c, star2.c, chaos2.c, ring2.c,
содержатся тестовые процедуры,
которые соответствуют различным
способам организации однонаправленных и двунаправленных
обменов между несколькими процессорами.
В файле env.c содержатся некоторые вспомогательные процедуры,
а в заголовочном файле env.h - вспомогательные
определения и прототипы.
Правило для сборки теста с помощью утилиты make описано в файле Makefile.
После успешной сборки создается исполняемый файл nettest,
который содержит включает в себя различные тестовые процедуры.
Пример запуска:
В данном случае тест будет запущен на 4 процессорах.
В качестве единицы длины сообщения будет выбран Килобайт (uK),
длина сообщения будет изменяться в геометрической прогрессии (K2)
от 1 до 16 Кбайт (m1 M16). Каждая
тестовая процедура будет состоять из 1000 итераций (T1000),
а весь тест будет повторен два раза (R2).
Результаты будут печататься в файл transfer.dat (otransfer.dat),
будут выдаваться значения суммарной пропускной способности сети (Ptotal).
Вот пример выдачи теста с указанными параметрами:
Здесь мы видим, что наилучшая пропускная способность
сети для 4 процессоров достигается на топологии "кольцо"
при двунаправленных обменах и составляет примерно 40 Мбайт/сек.
Методики тестирования для однонаправленные обменов
Каждый из узлов 1,2,...,P-1
использует блокирующую операцию MPI_Recv для приема сообщения от узла 0;
а затем посылает узлу 0 свое сообщение с помошью MPI_Send.
Каждый узел i имеет P-1 соседей: 0,..., i - 1, i + 1,... P-1.
Для узла с номером i это узлы с номерами r = (i+1) (mod P) и l = (i-1)(mod P),
называемые соответственно правым и левым соседями для i.
Особенности реализации
Сборка теста
Параметры теста
mpirun -np 4 nettest uK m1 M16 K2 R2 T1000 Ptotal otransfer.dat
NETTEST/MPI of 2003/07/08 is running with following parameters:
Message length unit is 1Kb = 1024 bytes
Messages: 1 to 16 units, step 0, multiplier 2
1000 times for each test routine, 2 iterations for whole test
Running chaos test with 6 logical links used.
Nodes: aqua1-1.the.net aqua1-2.the.net aqua1-3.the.net aqua2-1.the.net
Network throughput values in MB/sec
Size,K Star Star2 Chaos Chaos2 Ring Ring2
1 8.38 16.44 15.88 23.73 15.08 21.85
2 9.95 20.08 19.04 27.62 20.57 26.95
4 12.83 21.47 22.89 31.83 27.61 33.44
8 14.19 21.41 23.58 34.22 32.71 36.83
16 15.03 21.34 25.19 35.05 36.48 39.59
1 8.35 15.00 15.83 23.79 15.51 21.92
2 10.23 20.08 19.26 27.64 20.48 26.92
4 12.81 21.47 22.19 32.14 27.88 33.46
8 14.15 21.42 23.67 34.17 32.79 36.50
16 15.05 21.23 25.16 35.27 36.66 38.59
MPI Network Test complete in 125.51 sec
Best network throughput values in MB/sec
Star Star2 Chaos Chaos2 Ring Ring2
15.05 21.47 25.19 35.27 36.66 39.59