© Воеводин Вл.В.
Курс лекций
"Параллельная обработка данных"
Лекция 4. Архитектура массивно-параллельных компьютеров (на примере CRAY T3D). Особенности программирования
План лекции:
- Массивно-параллельные компьютеры, общие черты
- Общая структура компьютера CRAY T3D
- Вычислительные узлы и процессорные элементы
- Коммуникационная сеть
- Особенности синхронизации процессорных элементов
- Факторы, снижающие производительность параллельных компьютеров
Массивно-параллельные компьютеры, общие черты
Основные причины появления массивно-параллельных компьютеров - это, во-первых, необходимость построения компьютеров с гигантской производительностью, и, во-вторых, необходимость производства компьютеров в большом диапазоне как производительности, так и стоимости. Не все в состоянии купить однопроцессорный CRAY Y-MP C90, да и не всегда такие мощности и нужны. Для массивно-параллельного компьютера, в котором число процессоров может сильно меняться, всегда можно подобрать конфигурацию с заранее заданной производительностью и/или стоимостью.
С некоторой степенью условности, массивно-параллельные компьютеры можно характеризовать следующими параметрами:
- используемые микропроцессоры: Intel Paragon - i860, IBM SP2 - PowerPC 604e или Power2 SC, CRAY T3D - DEC ALPHA;
- коммуникационная сеть: Intel Paragon - двумерная прямоугольная решетка, IBM SP2 - коммутатор, CRAY T3D - трехмерный тор;
- организация памяти: Intel Paragon, IBM SP2, CRAY T3D - распределенная память;
- наличие или отсутствие host-компьютера: Intel Paragon, IBM SP2 - нет, CRAY T3D - есть.
Общая структура компьютера CRAY T3D

|
Компьютер CRAY T3D - это массивно-параллельный компьютер с распределенной памятью, объединяющий от 32 до 2048 процессоров. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к своей локальной памяти, а доступ к данным, расположенным в памяти других процессоров, выполняется другими, более сложными способами. CRAY T3D подключается к хост-компьютеру (главному или ведущему), роль которого, в частности, может исполнять CRAY Y-MP C90. Вся предварительная обработка и подготовка программ, выполняемых на CRAY T3D, проходит на хосте (например, компиляция). Связь хост-машины и T3D идет через высокоскоростной канал передачи данных с производительностью 200 Mбайт/с. Массивно-параллельный компьютер CRAY T3D работает на тактовой частоте 150MHz и имеет в своем составе три основные компоненты: сеть межпроцессорного взаимодействия (или по-другому коммуникационную сеть), вычислительные узлы и узлы ввода/вывода. |
Вычислительные узлы и процессорные элементы
Вычислительный узел состоит из двух процессорных элементов (ПЭ), сетевого интерфейса контроллера блочных передач. Оба процессорных элемента, входящие в состав вычислительного узла, идентичны и могут работать независимо друг от друга.
Процессорный элемент. Каждый ПЭ содержит микропроцессор, локальную память и некоторые вспомогательные схемы.
Микропроцессор - это 64-х разрядный RISC (Reduced Instruction Set Computer) процессор ALPHA фирмы DEC, работающий на тактовой частоте 150 MHz. Микропроцессор имеет внутреннюю кэш-память команд и кэш-память данных.
Объем локальной памяти ПЭ - 8 Mслов. Локальная память каждого процессорного элемента является частью физически распределенной, но логически разделяемой (или общей), памяти всего компьютера. В самом деле, память физически распределена, так как каждый ПЭ содержит свою локальную память. В тоже время, память разделяется всеми ПЭ, так как каждый ПЭ может обращаться к памяти любого другого ПЭ, не прерывая его работы.
Обращение к памяти другого ПЭ лишь в 6 раз медленнее, чем обращение к своей собственной локальной памяти.
Сетевой интерфейс формирует передачи перед посылкой через коммуникационную сеть другим вычислительным узлам или узлам ввода/вывода, а также принимает приходящие сообщения и распределяет их между двумя процессорными элементами узла.
Контроллер блочных передач - это контроллер асинхронного прямого доступа в память, который помогает перераспределять данные, расположенные в локальной памяти разных ПЭ компьютера CRAY T3D, без прерывания работы самих ПЭ.
Коммуникационная сеть
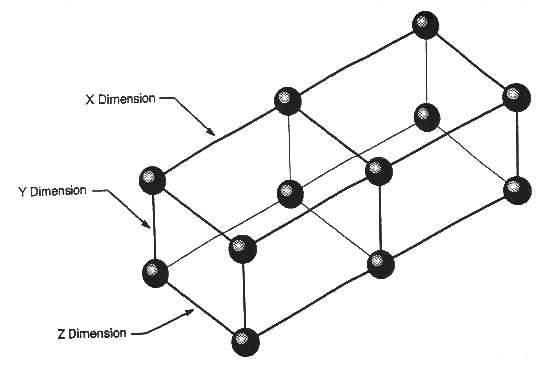
Коммуникационная сеть обеспечивает передачу информации между вычислительными узлами и узлами ввода/вывода с максимальной скоростью в 140M байт/с. Сеть образует трехмерную решетку, соединяя сетевые маршрутизаторы узлов в направлениях X, Y, Z. Каждая элементарная связь между двумя узлами - это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
Топология сети, чередование вычислительных узлов

Коммуникационная сеть компьютера CRAY T3D организована в виде двунаправленного трехмерного тора, что имеет свои преимущества перед другими способами организации связи:
- быстрая связь граничных узлов и небольшое среднее число перемещений по тору при взаимодействии разных ПЭ: максимальное расстояние в сети для конфигурации из 128 ПЭ равно 6, а для 2048 ПЭ равно 12;
- возможность выбора другого маршрута для обхода поврежденных связей.
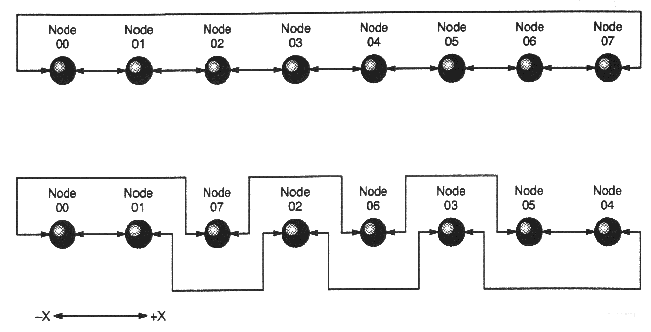
Все узлы в коммуникационной сети в размерностях X и Z расположены с чередованием, что позволяет минимизировать длину максимального физического соединения между ПЭ.
Маршрутизация в сети и сетевые маршрутизаторы.
При выборе маршрута для обмена данными между двумя узлами сетевые маршрутизаторы всегда сначала выполняют смещение по размерности X, затем по Y, а в конце по Z. Так как смещение может быть как положительным, так и отрицательным, то этот механизм помогает минимизировать число перемещений по сети и обойти поврежденные связи.
Сетевые маршрутизаторы каждого вычислительного узла определяют путь перемещения каждого пакета и могут осуществлять параллельный транзит данных по каждому из трех измерений X, Y, Z.
Нумерация вычислительных узлов.
Каждому ПЭ в системе присвоен уникальный физический номер, определяющий его физическое расположение, который и используется непосредственно аппаратурой.
Не обязательно все физические ПЭ принимают участие в формировании логической
конфигурации компьютера. Например, 512-процессорная конфигурация компьютера
CRAY T3D реально содержит 520 физических ПЭ,
8 из которых находятся в резерве. Каждому физическому ПЭ присваиваится
логический номер, определяющий его расположение в логической конфигурации
компьютера, которая уже и образует трехмерный тор.

Каждой программе пользователя из трехмерной решетки вычислительных узлов выделяется отдельный раздел, имеющий форму прямоугольного параллелепипеда, на котором работает только данная программа (не считая компонент ОС). Для последовательной нумерации ПЭ, выделенных пользователю, вводится виртуальная нумерация.
Особенности синхронизации процессорных элементов
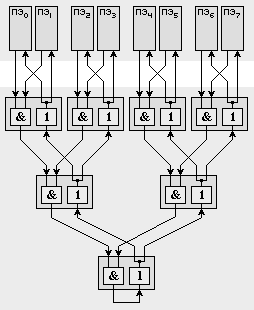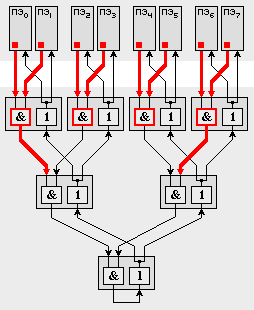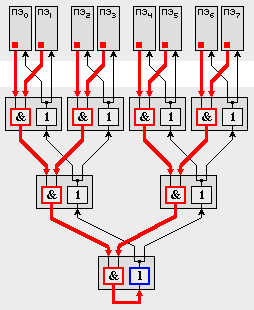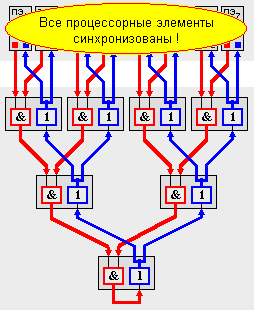
Для поддержки синхронизации процессорных элементов предусмотрена аппаратная реализация одного из наиболее "тяжелых" видов синхронизации - барьеров синхронизации. Барьер - это точка в программе, при достижении которой каждый процессор должен ждать до тех пор, пока остальные также не дойдут до барьера, и лишь после этого момента все процессы могут продолжать работу дальше.
В схемах поддержки каждого ПЭ предусмотрены два 8-ми разрядных регистра, причем каждый разряд регистров соединен со своей независимой цепью реализации барьера (всего 16 независимых цепей). Каждая цепь строится на основе схем AND и ДУБЛИРОВАНИЕ (1-2). До барьера соответствующие разряды на всех ПЭ обнуляются, а как только процесс на ПЭ доходит до барьера, то записывает в свой разряд единицу. На выходе схемы AND появляется единица только в том случае, когда на обоих входах выставлены 1. Устройство 1-2 просто дублирует свой вход на выходы:
Если схемы AND заменить на OR, то получится цепь для реализации механизма "эврика": как только один ПЭ выставил значение 1, эта единица распространяется всем ПЭ, сигнализируя о некотором событии на ПЭ. Это исключительно полезно, например, в задачах поиска.
Факторы, снижающие производительность параллельных компьютеров
Начнем с уже упоминавшегося закона Амдала. Для массивно-параллельных компьютеров он играет еще большую роль, чем для векторно-конвейерных. В самом деле, в таблице 1 показано, на какое максимальное ускорение работы программы можно рассчитывать в зависимости от доли последовательных вычислений и числа доступных процессоров. Предполагается, что параллельная секция может быть выполнена без каких-либо дополнительных накладных расходов. Так как в программе всегда присутствует инициализация, ввод/вывод и некоторые сугубо последовательные действия, то недооценивать данный фактор никак нельзя - практически вся программа должна исполняться в параллельном режиме, что можно обеспечить только после анализа всей (!) программы.
|
ПЭ | Доля последовательных вычислений | ||||
Табл. 1. Максимальное ускорение работы программы в зависимости от доли последовательных вычислений и числа используемых процессоров. | |||||
Поскольку CRAY T3D - это компьютер
с распределенной памятью, то взаимодействие процессоров, в основном,
осуществляется посредством передачи сообщений друг другу.
Отсюда два других замедляющих
фактора - время инициализации посылки сообщения (латентность) и
собственно
время передачи сообщения по сети. Максимальная скорость передачи
достигается на больших сообщениях, когда латентность, возникающая лишь в
начале, не столь заметна на фоне непосредственно передачи данных.
Возможность асинхронной посылки сообщений и вычислений. Если или аппаратура, или программное обеспечение не поддерживают возможности проводить вычислений на фоне пересылок, то возникнут неизбежные накладные расходы, связанные с ожиданием полного завершения взаимодействия параллельных процессов.
Для достижения эффективной параллельной обработки необходимо добиться равномерной загрузки всех процессоров. Если равномерности нет, то часть процессоров неизбежно будет простаивать, ожидая остальных, хотя в этот момент они могли бы выполнять полезную работу. Иногда равномерность получается автоматически, например, при обработке прямоугольных матриц достаточно большого размера, однако уже при переходе к треугольным матрицам добиться хорошей равномерности не так просто.
Если один процессор должен вычислить некоторые данные, которые нужны другому процессору, и если второй процесс первым дойдет до точки приема соответствующего сообщения, то он с неизбежностью будет простаивать, ожидая передачи. Для того чтобы минимизировать время ожидание прихода сообщения первый процесс должен отправить требуемые данные как можно раньше, отложив независящую от них работу на потом, а второй процесс должен выполнить максимум работы, не требующей ожидаемой передачи, прежде, чем выходить на точку приема сообщения.
Чтобы не сложилось совсем плохого впечатления о массивно-параллельных компьютерах, надо заканчивать с негативными факторами, потому последний фактор - это реальная производительность одного процессора. Разные модели микропроцессоров могут поддерживать несколько уровней кэш-памяти, иметь специализированные функциональные устройства, регистровую структуру и т.п. Каждый микропроцессор, в конце концов, может иметь векторно-конвейерную архитектуру и в этом случае ему присущи практически все те факторы, которые мы обсуждали в лекции, посвященной особенностям программирования векторно-конвейерных компьютеров.
К сожалению, на работу каждой конкретной программы сказываются в той или иной мере все эти факторы одновременно, дополнительно усугубляя ситуацию с эффективностью параллельных программ. Однако в отличие от векторно-конвейерных компьютеров все изложенные здесь факторы, за исключением быть может последнего, могут снизить производительность не в десятки, а в сотни и даже тысячи раз по сравнению с пиковыми показателями производительности компьютера. Добиться на этих компьютерах, в принципе, можно многого, но усилий это может потребовать во многих случаях очень больших.
|
|
|
© Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ