© Крюков В.А.
Курс лекций
"Распределенные ОС"
7. Обеспечение надежности в распределенных системах
Отказом системы называется поведение системы, не удовлетворяющее ее спецификациям. Последствия отказа могут быть различными.
Отказ системы может быть вызван отказом (неверным срабатыванием) каких-то ее компонентов (процессор, память, устройства ввода/вывода, линии связи, или программное обеспечение).
Отказ компонента может быть вызван ошибками при конструировании, при производстве или программировании. Он может быть также вызван физическим повреждением, изнашиванием оборудования, некорректными входными данными, ошибками оператора, и многими другими причинами.
Отказы могут быть случайными, периодическими или постоянными.
Случайные отказы (сбои) при повторении операции исчезают.
Причиной такого сбоя может служить, например, электромагнитная помеха от проезжающего мимо трамвая. Другой пример - редкая ситуация в последовательности обращений к операционной системе от разных задач.
Периодические отказы повторяются часто в течение какого-то времени, а затем могут долго не происходить. Примеры - плохой контакт, некорректная работа ОС после обработки аварийного завершения задачи.
Постоянные (устойчивые) отказы не прекращаются до устранения их причины - разрушения диска, выхода из строя микросхемы или ошибки в программе.
Отказы по характеру своего проявления подразделяются на византийские (система активна и может проявлять себя по-разному, даже злонамеренно) и пропажа признаков жизни (частичная или полная). Первые распознать гораздо сложнее, чем вторые. Свое название они получили по имени Византийской империи (330-1453 гг.), где расцветали конспирация, интриги и обман.
Для обеспечения надежного решения задач в условиях отказов системы применяются два принципиально различающихся подхода - восстановление решения после отказа системы (или ее компонента) и предотвращение отказа системы (отказоустойчивость).
7.1. Восстановление после отказа.
Восстановление может быть прямым (без возврата к прошлому состоянию) и возвратное.
Прямое восстановление основано на своевременном обнаружении сбоя и ликвидации его последствий путем приведения некорректного состояния системы в корректное. Такое восстановление возможно только для определенного набора заранее предусмотренных сбоев.
При возвратном восстановлении происходит возврат процесса (или системы) из некорректного состояния в некоторое из предшествующих корректных состояний. При этом возникают следующие проблемы.
(1) Потери производительности, вызванные запоминанием состояний, восстановлением запомненного состояния и повторением ранее выполненной работы, могут быть слишком высоки.
(2) Нет гарантии, что сбой снова не повторится после восстановления.
(3) Для некоторых компонентов системы восстановление в предшествующее состояние может быть невозможно (торговый автомат).
Тем не менее этот подход является более универсальным и применяется гораздо чаще первого. Дальнейшее рассмотрение будет ограничено только данным подходом.
Для восстановления состояния в традиционных ЭВМ применяются два метода (и их комбинация), основанные на промежуточной фиксации состояния либо ведении журнала выполняемых операций. Они различаются объемом запоминаемой информацией и временем, требуемым для восстановления.
Применение подобных методов в распределенных системах наталкивается на следующие трудности.
7.1.1. Сообщения-сироты и эффект домино.
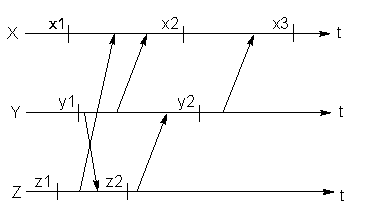
На рисунке показаны три процесса (X,Y,Z), взаимодействующие через сообщения. Вертикальные черточки показывают на временной оси моменты запоминания состояния процесса для восстановления в случае отказа. Стрелочки соответствуют сообщениям и показывают моменты их отправления и получения.
Если процесс X сломается, то он может быть восстановлен с состояния x3 без какого-либо воздействия на другие процессы.
Предположим, что процесс Y сломался после посылки сообщения m и был возвращен в состояние y2. В этом случае получение сообщения m зафиксировано в x3, а его посылка не отмечена в y2. Такая ситуация, возникшая из-за несогласованности глобального состояния, не должна допускаться (пример - сообщение содержит сумму, переводимую с одного счета на другой). Сообщение m в таком случае называется сообщением-сиротой. Процесс X должен быть возвращен в предыдущее состояние x2 и конфликт будет ликвидирован.
Предположим теперь, что процесс Z сломается и будет восстановлен в состояние z2. Это приведет к откату процесса Y в y1, а затем и процессов X и Z в начальные состояния x1 и y1. Этот эффект известен как эффект домино.
7.1.2. Потеря сообщений.
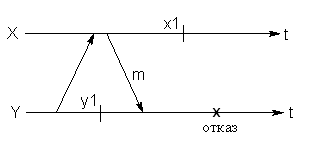
Предположим, что контрольные точки x1 и y1 зафиксированы для восстановления процессов X и Y, соответственно.
Если процесс Y сломается после получения сообщения m, и оба процесса будут восстановлены (x1,y1), то сообщение m будет потеряно (его потеря будет неотличима от потери в канале).
- Проблема бесконечного восстановления.
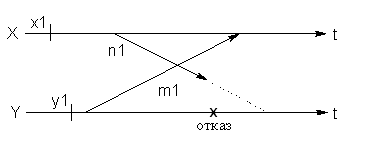
Процесс Y сломался до получения сообщения n1 от X. Когда Y
вернулся в состояние y1, в нем не оказалось записи о посылке сообщения m1. Поэтому X должен вернуться в состояние x1.
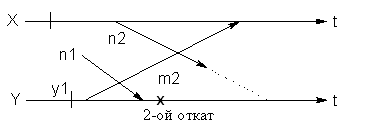
После отката Y посылает m2 и принимает n1 (сообщение-призрак). Процесс X после отката к x1 посылает n2 и принимает m2. Однако X после отката уже не имеет записи о посылке n1. Поэтому Y должен повторно откатиться к y1. Теперь X должен откатиться к x1, поскольку он принял m2, о посылке которого в Y нет записи. Эта ситуация будет повторяться бесконечно.
7.1.4. Консистентное множество контрольных точек.
Описанные выше трудности показывают, что глобальная контрольная точка, состоящая из произвольной совокупности локальных контрольных точек, не обеспечивает восстановления взаимодействующих процессов.
Для распределенных систем запоминание согласованного глобального состояния является серьезной теоретической проблемой.
Множество контрольных точек называется строго консистентным, если во время его фиксации никаких обменов между процессами не было. Оно соответствует понятию строго консистентного глобального состояния, когда все посланные сообщения получены и нет никаких сообщений в каналах связи. Множество контрольных точек называется консистентным, если для любой зафиксированной операции приема сообщения, соответствующая операция посылки также зафиксирована (нет сообщений-сирот).
Простой метод фиксации консистентного множества контрольных точек - фиксация локальной контрольной точки после каждой операции посылки сообщения. При этом посылка сообщения и фиксация должны быть единой неделимой операцией (транзакцией). Множество последних локальных контрольных точек является консистентным (но не строго консистентным).
Чтобы избежать потерь сообщений при восстановлении с использованием консистентного множества контрольных точек необходимо повторить отправку тех сообщений, квитанции о получении которых стали недействительными в результате отката. Используя временные метки сообщений можно распознавать сообщения-призраки и избежать бесконечного восстановления.
7.1.5. Синхронная фиксация контрольных точек и восстановление
.Ниже описываются алгоритмы создания консистентного множества контрольных точек и использования их для восстановления без опасности бесконечного зацикливания.
Алгоритм создания консистентного множества контрольных точек.
К распределенной системе алгоритм предъявляет следующие требования.
(1) Процессы взаимодействуют посредством посылки сообщений через коммуникационные каналы.
(2) Каналы работают по алгоритму FIFO. Коммуникационные протоколы точка-точка гарантируют невозможность пропажи сообщений из-за ошибок коммуникаций или отката к контрольной точке. (Другой способ обеспечения этого - использование стабильной памяти для журнала посылаемых сообщений и фиксации идентификатора последнего полученного по каналу сообщения).
Алгоритм создает в стабильной памяти два вида контрольных точек - постоянные и пробные.
Постоянная контрольная точка - это локальная контрольная точка, являющаяся частью консистентной глобальной контрольной точки. Пробная контрольная точка - это временная контрольная точка, которая становится постоянной только в случае успешного завершения алгоритма. Алгоритм исходит из того, что только один процесс инициирует создание множества контрольных точек, а также из того, что никто из участников не сломается во время работы алгоритма.
Алгоритм выполняется в две фазы.
1-ая фаза.
Инициатор фиксации (процесс Pi) создает пробную контрольную точку и просит все остальные процессы сделать то же самое. При этом процессу запрещается посылать неслужебные сообщения после того, как он сделает пробную контрольную точку. Каждый процесс извещает Pi о том, сделал ли он пробную контрольную точку. Если все процессы сделали пробные контрольные точки, то Pi принимает решение о превращении пробных точек в постоянные. Если какой-либо процесс не смог сделать пробную точку, то принимается решение об отмене всех пробных точек.
2-ая фаза.
Pi информирует все процессы о своем решении. В результате либо все процессы будут иметь новые постоянные контрольные точки, либо ни один из процессов не создаст новой постоянной контрольной точки. Только после выполнения принятого процессом Pi решения все процессы могут посылать сообщения.
Корректность алгоритма очевидна, поскольку созданное всеми множество постоянных контрольных точек не может содержать не зафиксированных операций посылки сообщений.
Оптимизация: если процесс не посылал сообщения с момента фиксации предыдущей постоянной контрольной точки, то он может не создавать новую.
Алгоритм отката (восстановления).
Алгоритм предполагает, что его инициирует один процесс и он не будет выполняться параллельно с алгоритмом фиксации.
Выполняется в две фазы.
1-ая фаза.
Инициатор отката спрашивает остальных, готовы ли они откатываться. Когда все будут готовы к откату, то он принимает решение об откате.
2-ая фаза.
Pi сообщает всем о принятом решении. Получив это сообщение, каждый процесс поступает указанным образом. С момента ответа на опрос готовности и до получения принятого решения процессы не должны посылать сообщения (нельзя же посылать сообщение процессу, который уже мог успеть откатиться).
Оптимизация: если процесс не обменивался сообщениями с момента фиксации предыдущей постоянной контрольной точки, то он может к ней не откатываться.
7.1.6. Асинхронная фиксация контрольных точек и восстановление.
Синхронная фиксация упрощает восстановление, но связана с большими накладными расходами:
- Дополнительные служебные сообщения для реализации алгоритма.
- Синхронизационная задержка - нельзя посылать неслужебные сообщения во время работы алгоритма.
Если отказы редки, то указанные потери совсем не оправданы.
Фиксация может производиться асинхронно. В этом случае множество контрольных точек может быть неконсистентным. При откате происходит поиск подходящего консистентного множества путем поочередного отката каждого процесса в ту точку, в которой зафиксированы все посланные им и полученные другими сообщения (для ликвидации сообщений-сирот). Алгоритм опирается на наличие в стабильной памяти для каждого процесса журнала, отслеживающего номера посланных и полученных им сообщений, а также на некоторые предположения об организации взаимодействия процессов, необходимые для исключения эффекта домино (например, организация приложения по схеме сообщение-реакция-ответ).
7.2. Отказоустойчивость.
Изложенные выше методы восстановления после отказов для некоторых систем непригодны (управляющие системы, транзакции в on-line режиме) из-за прерывания нормального функционирования.
Чтобы избежать эти неприятности, создают системы, устойчивые к отказам. Такие системы либо маскируют отказы, либо ведут себя в случае отказа заранее определенным образом (пример - изменения, вносимые транзакцией в базу данных, становятся невидимыми при отказе).
Два механизма широко используются при обеспечении отказоустойчивости - протоколы голосования и протоколы принятия коллективного решения.
Протоколы голосования служат для маскирования отказов (выбирается правильный результат, полученный всеми исправными исполнителями).
Протоколы принятия коллективного решения подразделяются на два класса. Во-первых, протоколы принятия единого решения, в которых все исполнители являются исправными и должны либо все принять, либо все не принять заранее предусмотренное решение. Примерами такого решения являются решение о завершении итерационного цикла при достижении всеми необходимой точности, решение о реакции на отказ (этот протокол уже знаком нам - он использовался для принятия решения об откате всех процессов к контрольным точкам). Во-вторых, протоколы принятия согласованных решений на основе полученных друг от друга данных. При этом необходимо всем исправным исполнителям получить достоверные данные от остальных исправных исполнителей, а данные от неисправных исполнителей проигнорировать.
Ключевой подход для обеспечения отказоустойчивости - избыточность (оборудования, процессов, данных).
- Использование режима горячего резерва (второй пилот, резервное ПО).
Проблема переключения на резервный исполнитель.
7.2.2. Использование активного размножения.
Наглядный пример - тройное дублирование аппаратуры в бортовых компьютерах и голосование при принятии решения.
Другие примеры √ размножение страниц в DSM и размножение файлов в распределенных файловых системах. При этом очень важным моментом является наличие механизма неделимых широковещательных рассылок сообщений (они должны приходить всем в одном порядке).
Алгоритмы голосования.
Общая схема использования голосования при размножении файлов может быть представлена следующим образом.
Файл может модифицироваться разными процессами только последовательно, а читаться всеми одновременно (протокол писателей-читателей). Все модификации файла нумеруются и каждая копия файла характеризуется номером версии √ количеством ее модификаций. Каждой копии приписано некоторое количество голосов Vi. Пусть общее количество приписанных всем копиям голосов равно V. Определяется кворум записи Vw и кворум чтения Vr так, что
Vw > V/2 и Vw +Vr > V
Для записи требуется запросить разрешение у всех серверов и получить соответствующее количество (Vw) голосов от тех из них, кто владеет текущей версией копии (при получении разрешения процесс одновременно с количеством приписанных копии голосов получает и ее номер версии). Если его копия устарела (имеет меньший номер версии, чем максимальный из полученных номеров), то до модификации копии ее надо обновить.
Кворум записи выбран так, что два процесса не смогут одновременно получить разрешение на запись.
Выполнив модификацию, процесс рассылает ее всем владельцам текущей версии файла.
Для чтения достаточно получить необходимое число голосов (Vr) от любых серверов. Кворум чтения выбран так, что хотя бы один из тех серверов, от которых получено разрешение, является владельцем текущей копии файла. Необходимо отметить, что при одновременном запросе разрешений на запись несколькими процессами, возможна ситуация, когда голоса разделятся и ни один из процессов не получит кворума. Для выхода из таких ситуаций процессы должны по истечению тайм-аута отказаться от своего запроса (сообщить об этом всем серверам, приславшим им разрешения), а затем повторить запрос.
Описанная схема базируется на статическом распределении голосов. Различие в голосах, приписанных разным серверам, позволяет учесть их особенности (надежность, эффективность). Еще большую гибкость предоставляет метод динамического перераспределения голосов.
Для того, чтобы выход из строя некоторых серверов не привел к ситуации, когда невозможно получить кворум, применяется механизм изменения состава голосующих.
Протоколы принятия единого решения
Необходимо отметить, что в условиях отсутствия надежных коммуникаций (с ограниченным временем задержки) не может быть алгоритма достижения единого решения. Рассмотрим известную проблему двух армий.
Армия зеленых численностью 5000 воинов располагается в долине.
Две армии синих численностью по 3000 воинов находятся далеко друг от друга в горах, окружающих долину. Если две армии синих одновременно атакуют зеленых, то они победят. Если же в сражение вступит только одна армия синих, то она будет полностью разбита.
Предположим, что командир 1-ой синей армии генерал Александр посылает (с посыльным) сообщение командиру 2-ой синей армии генералу Михаилу Я имею план - давай атаковать завтра на рассвете. Посыльный возвращается к Александру с ответом Михаила - Отличная идея, Саша. Увидимся завтра на рассвете. Александр приказывает воинам готовиться к атаке на рассвете.
Однако, чуть позже Александр вдруг осознает, что Михаил не знает о возвращении посыльного и поэтому может не отважиться на атаку. Тогда он отправляет посыльного к Михаилу чтобы подтвердить, что его (Михаила) сообщение получено Александром и атака должна состояться.
Посыльный прибыл к Михаилу, но теперь тот боится, что не зная о прибытии посыльного Александр может не решиться на атаку. И т.д. Ясно, что генералы никогда не достигнут согласия.
Предположим, что такой протокол согласия c конечным числом сообщений существует. Удалив избыточные последние сообщения, получим минимальный протокол. Самое последнее сообщение является существенным (поскольку протокол минимальный). Если это сообщение не дойдет по назначению, то войны не будет. Но тот, кто посылал это сообщение, не знает, дошло ли оно. Следовательно, он не может считать протокол завершенным и не может принять решение об атаке. Даже с надежными процессорами (генералами), принятие единого решения невозможно при ненадежных коммуникациях.
Теперь предположим, что коммуникации надежны, а процессоры нет.
Классический пример протокола принятия согласованных решений - задача Византийских генералов.
В этой задаче армия зеленых находится в долине, а n синих генералов возглавляют свои армии, расположенные в горах. Связь осуществляется по телефону и является надежной, но из n генералов m являются предателями. Предатели активно пытаются воспрепятствовать согласию лояльных генералов.
Согласие в данном случае заключается в следующем. Каждый генерал знает, сколько воинов находится под его командой. Ставится цель, чтобы все лояльные генералы узнали численности всех лояльных армий, т.е. каждый из них получил один и тот же вектор длины n, в котором i-ый элемент либо содержит численность i-ой армии (если ее командир лоялен) либо не определен (если командир предатель).
Соответствующий рекурсивный алгоритм был предложен в 1982 г. (Lamport).
Проиллюстрируем его для случая n=4 и m=1. В этом случае алгоритм осуществляется в 4 шага.
1 шаг. Каждый генерал посылает всем остальным сообщение, в котором указывает численность своей армии. Лояльные генералы указывают истинное количество, а предатели могут указывать различные числа в разных сообщениях. Генерал-1 указал 1 (одна тысяча воинов), генерал-2 указал 2, генерал-3 указал трем остальным генералам соответственно x,y,z, а генерал-4 указал 4.
2-ой шаг. Каждый формирует свой вектор из имеющейся информации.
Получается:
vect1 (1,2,x,4)
vect2 (1,2,y,4)
vect3 (1,2,3,4)
vect4 (1,2,z,4)
3-ий шаг. Каждый посылает свой вектор всем остальным (генерал-3 посылает опять произвольные значения).
Генералы получают следующие вектора:
|
g1 |
g2 |
g3 |
g4 |
|
(1,2,y,4) |
(1,2,x,4) |
(1,2,x,4) |
(1,2,x,4) |
|
(a,b,c,d) |
(e,f,g,h) |
(1,2,y,4) |
(1,2,y,4) |
|
(1,2,z.4) |
(1,2,z.4) |
(1,2,z.4) |
(i,j,k.l) |
4-ый шаг. Каждый генерал проверяет каждый элемент во всех полученных векторах. Если какое-то значение совпадает по меньшей мере в двух векторах, то оно помещается в результирующий вектор, иначе соответствующий элемент результирующего вектора помечается неизвестен.
Все лояльные генералы получают один вектор (1,2,неизвестен,4) - согласие достигнуто.
Если рассмотреть случай n=3 и m=1, то согласие не будет достигнуто.
Lamport доказал, что в системе с m неверно работающими процессорами можно достичь согласия только при наличии 2m+1 верно работающих процессоров (более 2/3).
Другие авторы доказали, что в распределенной системе с асинхронными процессорами и неограниченными коммуникационными задержками согласие невозможно достичь даже при одном неработающем процессоре (даже если он не подает признаков жизни).
Применение алгоритма - надежная синхронизация часов.
Алгоритм надежных неделимых широковещательных рассылок сообщений.
Алгоритм выполняется в две фазы и предполагает наличие в каждом процессоре очередей для запоминания поступающих сообщений. В качестве уникального идентификатора сообщения используется его начальный приоритет - логическое время отправления, значение которого на разных процессорах различно.
1-ая фаза.
Процесс-отправитель посылает сообщение группе процессов (список их идентификаторов содержится в сообщении).
При получении этого сообщения процессы:
- Приписывают сообщению приоритет, помечают сообщение как недоставленное и буферизуют его. В качестве приоритета используется временная метка (текущее логическое время).
- Информируют отправителя о приписанном сообщению приоритете.
2-ая фаза.
При получении ответов от всех адресатов, отправитель:
- Выбирает из всех приписанных сообщению приоритетов максимальный и устанавливает его в качестве окончательного приоритета сообщения.
- Рассылает всем адресатам этот приоритет.
Получив окончательный приоритет, получатель:
- Приписывает сообщению этот приоритет.
- Помечает сообщение как доставленное.
- Упорядочивает все буферизованные сообщения по возрастанию их приписанных приоритетов.
- Если первое сообщение в очереди отмечено как доставленное, то оно будет обрабатываться как окончательно полученное.
Если получатель обнаружит, что он имеет сообщение с пометкой недоставленное, отправитель которого сломался, то он для завершения выполнения протокола осуществляет следующие два шага в качестве координатора.
1. Опрашивает всех получателей о статусе этого сообщения.
Получатель может ответить одним из трех способов:
- Сообщение отмечено как недоставленное и ему приписан такой-то приоритет.
- Сообщение отмечено как доставленное и имеет такой-то окончательный приоритет.
- Он не получал это сообщение.
2. Получив все ответы координатор выполняет следующие действия:
- Если сообщение у какого-то получателя помечено как доставленное, то его окончательный приоритет рассылается всем. (Получив это сообщение каждый процесс выполняет шаги фазы 2).
- Иначе координатор заново начинает весь протокол с фазы 1. (Повторная посылка сообщения с одинаковым приоритетом не должна вызывать коллизий).
Необходимо заметить, что алгоритм требует хранения начального и окончательного приоритетов даже для принятых и уже обработанных сообщений.
|
|
© Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ