9.4.1. Data Access Routines



Up: Data Access Next: Positioning Previous: Data Access
Data is moved between files and processes by issuing read and write calls. There are three orthogonal aspects to data access: positioning (explicit offset vs. implicit file pointer), synchronism (blocking vs. nonblocking and split collective), and coordination (noncollective vs. collective). The following combinations of these data access routines, including two types of file pointers (individual and shared) are provided:
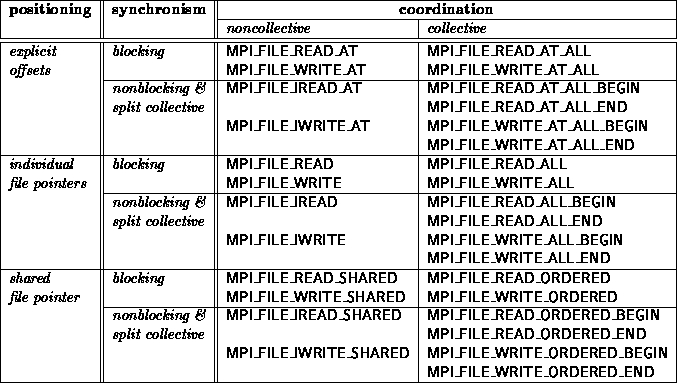
POSIX read()/fread() and write()/fwrite() are blocking, noncollective operations and use individual file pointers. The MPI equivalents are MPI_FILE_READ and MPI_FILE_WRITE.
Implementations of data access routines may buffer data to improve performance. This does not affect reads, as the data is always available in the user's buffer after a read operation completes. For writes, however, the MPI_FILE_SYNC routine provides the only guarantee that data has been transferred to the storage device.
Up: Data Access Next: Positioning Previous: Data Access
9.4.1.1. Positioning
Up: Data Access Routines Next: Synchronism Previous: Data Access Routines
MPI provides three types of positioning for data access routines: explicit offsets, individual file pointers, and shared file pointers. The different positioning methods may be mixed within the same program and do not affect each other.
The data access routines that accept explicit offsets contain _AT in their name (e.g., MPI_FILE_WRITE_AT). Explicit offset operations perform data access at the file position given directly as an argument---no file pointer is used nor updated. Note that this is not equivalent to an atomic seek-and-read or seek-and-write operation, as no ``seek'' is issued. Operations with explicit offsets are described in Section Data Access with Explicit Offsets .
The names of the individual file pointer routines contain no positional qualifier (e.g., MPI_FILE_WRITE). Operations with individual file pointers are described in Section Data Access with Individual File Pointers . The data access routines that use shared file pointers contain _SHARED or _ORDERED in their name (e.g., MPI_FILE_WRITE_SHARED). Operations with shared file pointers are described in Section Data Access with Shared File Pointers .
The main semantic issues with MPI-maintained file pointers are how and when they are updated by I/O operations. In general, each I/O operation leaves the file pointer pointing to the next data item after the last one that is accessed by the operation. In a nonblocking or split collective operation, the pointer is updated by the call that initiates the I/O, possibly before the access completes.
More formally,
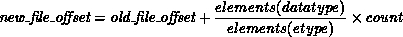
where count is the number of datatype items to be accessed,
elements(X) is the number of predefined datatypes in the typemap of X,
and 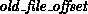 is
the value of the implicit offset before the call.
The file position,
is
the value of the implicit offset before the call.
The file position, 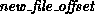 , is in terms
of a count of etypes relative to the current view.
, is in terms
of a count of etypes relative to the current view.
Up: Data Access Routines Next: Synchronism Previous: Data Access Routines
9.4.1.2. Synchronism
Up: Data Access Routines Next: Coordination Previous: Positioning
MPI supports blocking and nonblocking I/O routines.
A blocking I/O call will not return until the I/O request is completed.
A nonblocking I/O call initiates an I/O operation, but does not wait for it to complete. Given suitable hardware, this allows the transfer of data out/in the user's buffer to proceed concurrently with computation. A separate request complete call ( MPI_WAIT, MPI_TEST, or any of their variants) is needed to complete the I/O request, i.e., to confirm that the data has been read or written and that it is safe for the user to reuse the buffer. The nonblocking versions of the routines are named MPI_FILE_IXXX, where the I stands for immediate.
It is erroneous to access the local buffer of a nonblocking data access operation, or to use that buffer as the source or target of other communications, between the initiation and completion of the operation.
The split collective routines support a restricted form of ``nonblocking'' operations for collective data access (see Section Split Collective Data Access Routines ).
Up: Data Access Routines Next: Coordination Previous: Positioning
9.4.1.3. Coordination
Up: Data Access Routines Next: Data Access Conventions Previous: Synchronism
Every noncollective data access routine MPI_FILE_XXX has a collective counterpart. For most routines, this counterpart is MPI_FILE_XXX_ALL or a pair of MPI_FILE_XXX_BEGIN and MPI_FILE_XXX_END. The counterparts to the MPI_FILE_XXX_SHARED routines are MPI_FILE_XXX_ORDERED.
The completion of a noncollective call only depends on the activity of the calling process. However, the completion of a collective call (which must be called by all members of the process group) may depend on the activity of the other processes participating in the collective call. See Section Collective File Operations , for rules on semantics of collective calls.
Collective operations may perform much better than their noncollective counterparts, as global data accesses have significant potential for automatic optimization.
Up: Data Access Routines Next: Data Access Conventions Previous: Synchronism
9.4.1.4. Data Access Conventions
Up: Data Access Routines Next: Data Access with Explicit Offsets Previous: Coordination
Data is moved between files and processes by calling read and write routines. Read routines move data from a file into memory. Write routines move data from memory into a file. The file is designated by a file handle, fh. The location of the file data is specified by an offset into the current view. The data in memory is specified by a triple: buf, count, and datatype. Upon completion, the amount of data accessed by the calling process is returned in a status.
An offset designates the starting position in the file for an access. The offset is always in etype units relative to the current view. Explicit offset routines pass offset as an argument (negative values are erroneous). The file pointer routines use implicit offsets maintained by MPI.
A data access routine attempts to transfer (read or write) count data items of type datatype between the user's buffer buf and the file. The datatype passed to the routine must be a committed datatype. The layout of data in memory corresponding to buf, count, datatype is interpreted the same way as in MPI-1 communication functions; see Section 3.12.5 in [6]. The data is accessed from those parts of the file specified by the current view (Section File Views ). The type signature of datatype must match the type signature of some number of contiguous copies of the etype of the current view. As in a receive, it is erroneous to specify a datatype for reading that contains overlapping regions (areas of memory which would be stored into more than once).
The nonblocking data access routines indicate that MPI can start a data access and associate a request handle, request, with the I/O operation. Nonblocking operations are completed via MPI_TEST, MPI_WAIT, or any of their variants.
Data access operations, when completed, return the amount of data accessed in status.
[] Advice to users.
To prevent problems with the argument copying and register
optimization done by Fortran compilers, please note the hints
in subsections ``Problems Due to Data Copying and Sequence Association,''
and ``A Problem with Register Optimization'' in
Section A Problem with Register Optimization
,
.
( End of advice to users.)
For blocking routines, status is returned directly. For nonblocking routines and split collective routines, status is returned when the operation is completed. The number of datatype entries and predefined elements accessed by the calling process can be extracted from status by using MPI_GET_COUNT and MPI_GET_ELEMENTS, respectively. The interpretation of the MPI_ERROR field is the same as for other operations --- normally undefined, but meaningful if an MPI routine returns MPI_ERR_IN_STATUS. The user can pass (in C and Fortran) MPI_STATUS_IGNORE in the status argument if the return value of this argument is not needed. In C++, the status argument is optional. The status can be passed to MPI_TEST_CANCELLED to determine if the operation was cancelled. All other fields of status are undefined.
When reading, a program can detect the end of file by noting that the amount of data read is less than the amount requested. Writing past the end of file increases the file size. The amount of data accessed will be the amount requested, unless an error is raised (or a read reaches the end of file).
Up: Data Access Routines Next: Data Access with Explicit Offsets Previous: Coordination
Return to MPI-2 Standard Index
MPI-2.0 of July 18, 1997
HTML Generated on August 11, 1997