Общие сведения об архитектуре ГПУ
Современные ГПУ третьего поколения, такие, как NVidia GeForce 8-9 и AMD HD 2K-3K, содержат набор одинаковых вычислительных устройств (потоковых процессоров, ПП), работающих с общей памятью ГПУ (видеоОЗУ). Число ПП меняется от 4 до 128, размер видеоОЗУ может достигать 1 ГБ. Все ПП синхронно исполняют один и тот же шейдер, что позволяет отнести ГПУ к классу SIMD. За один проход, являющийся этапом вычислений на ГПУ, шейдер исполняется для всех точек двумерного массива. Система команд ПП включает арифметические команды для вещественных и целочисленных вычислений с 32-разрядной точностью, команды управления (ветвления и циклы), а также команды обращения к памяти. ГПУ выполняют операции только с данными на регистрах, число которых может достигать 128. Из-за высоких задержек (до 500 тактов) команды доступа к оперативной памяти выполняются асинхронно. С целью сокрытия задержек в очереди выполнения ГПУ может одновременно находиться до 512 потоков, и если текущий поток блокируется по доступу к памяти, на исполнение ставится следующий. Поскольку контекст потока полностью хранится на регистрах ГПУ, переключение осуществляется за 1 такт. За переключение потоков отвечает диспетчер потоков, который не является программируемым.
Тактовые частоты ГПУ ниже, чем у обычных процессоров, и лежат в диапазоне от 0,5 до 1,5 ГГц. Однако благодаря большому количеству потоковых процессоров производительность ГПУ весьма значительна. Современные ГПУ верхнего ценового сегмента имеют пик от 200 до 500 ГФлоп/c, что в сочетании с возможностью установки в одну машину двух графических карт позволяет получить пиковую производительность в 1 ТФлоп/c на одном персональном компьютере! Более того, на некоторых реальных задачах достигается до 70% пиковой производительности. Одновременно с этим, в сравнении с классическими кластерными системами, ГПУ обладают значительно лучшими характеристиками как по цене (менее $1 на ГФлоп/c), так и по энергопотреблению (менее 1Вт на ГФлоп/c).
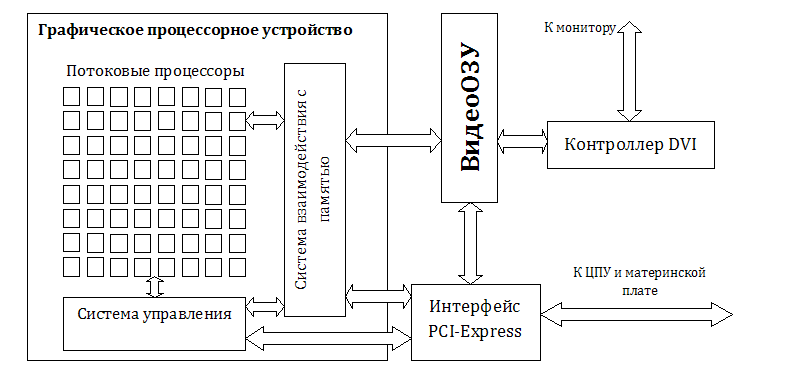
Общая схема графической карты, ГПУ и его соединения с системными устройствами.
Особенности архитектуры, влияющие на программирование:
- Высокая стоимость чтения из видеоОЗУ в шейдере на ГПУ. Время операции чтения из видеоОЗУ на два порядка больше времени выполнения одной арифметической операции.
- Большое время запуска прохода. Время запуска шейдера намного превышает время обработки одного элемента, и чтобы его компенсировать, требуется обрабатывать большое (10000 и более) количество элементов за 1 запуск.
- Поддержка аппаратной многопоточности. Если готовых к исполнению потоков будет мало, то высокую латентность обращения в видеоОЗУ скрыть не удастся.
- Медленный обмен данными между ОЗУ и видеоОЗУ. Канал обмена данными между оперативной ними является узким, что влияет на организацию программы.
- Разнородность архитектур. Следует учесть, что оптимальные программы для NVidia и AMD будут сильно различаться.
© Лаборатория Параллельных информационных технологий НИВЦ МГУ