Основная схема быстрого преобразования Фурье
- Вводные замечания
- Постановка задачи
- Случай составного N
- Сведение преобразования Фурье к последовательности преобразований меньшей размерности
- Размерность - степень двойки
- Размерность - чётная степень двойки
- Размерности, не являющиеся степенями двойки
- Ошибки округления и преобразование Фурье
- Заключение
Вводные замечания
Составной частью решения многих прикладных задач является осуществление прямого и обратного дискретных преобразований Фурье. Эта подзадача встречается в таких приложениях, как обработка сигналов, решение эллиптических задач математической физики, решение систем линейных алгебраических уравнений специального вида и т.д. Здесь мы рассмотрим, что это за преобразование и как его можно выполнить быстрее.
Постановка задачи
Пусть f = (f0, ... ,fN-1)T - исходный вектор, который нужно умножить на матрицу Фурье F c элементами
для получения вектора a= (a0, ..., aN-1)T по формуле a = Ff. Тогда для элемента искомого вектора умножение даст формулу:
Как известно, в общем случае умножение матрицы нам вектор требует O(N2) арифметических операций. Следует рассмотреть вопрос о сокращении этого числа.
1Вообще говоря, в формулах ДПФ для физической корректности часто присутствует и нормировочный множитель, которого у нас нет. Здесь мы будем использовать терминологию, принятую в § 17 справочника В.В.Воеводина и Ю.А.Кузнецова "Матрицы и вычисления" (М., Наука, 1984г.). Теоретические оценки, приводимые ниже, взяты тоже оттуда.
Структура вычислений классического ДПФ
Рассмотрим структуру вычислений классического ДПФ, предположив, что суммирование происходит по порядку от малых значений индексов к большим. Казалось бы, что сложного в банальном умножении матрицы на вектор? Однако, в отличие от стандартного умножения, где каждый элемент матрицы используется только один раз, в ДПФ матрица - специального вида. Это приводит к тому, что одни и те же элементы матрицы используются в совершенно разных местах схемы вычислений. На рисунке представлена структура ДПФ с N=6.
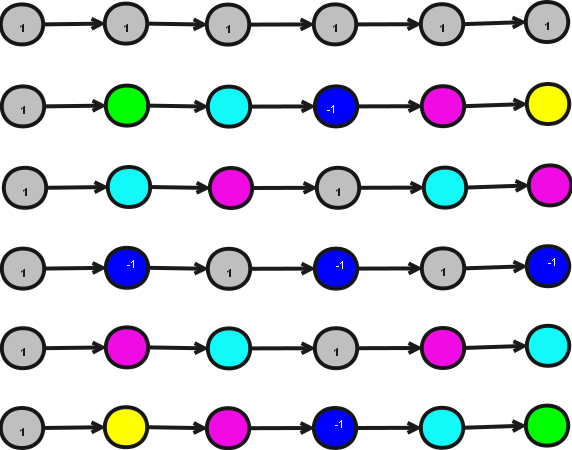
Чёрными линиями обозначены собственно ветви вычислений, при этом передачи осуществляются слева направо, в крайнем справа столбце результатом будет соответствующий элемент вычисляемого вектора. В одном столбце расположены те операции, которые используют в качестве одного из данных один и тот же элемент исходного вектора. А вот цвет вершины (все они соответствуют операции a+bc) соответствует тому, какой из элементов матрицы Фурье умножается на элемент исходного вектора. Серым цветом окрашены вершины, где из матрицы Фурье в качестве множителя берётся нулевая степень комплексного числа, т.е. просто единица (и где, следовательно, умножение можно пропустить). Как видим, её как раз больше всего в структуре вычислений. Далее степени одного и того же комплексного множителя растут от 1 до 5 в вершинах соответственно зелёного, голубого, синего (элемент там умножается на -1 и потому можно, как и в серых вершинах, отказаться от умножения, заменив сложение вычитанием), фиолетового и жёлтого цветов. Как видно, структура использования этих степеней довольно "хаотична", хотя на самом деле в этом "хаосе" есть строго определённый порядок.
В случае простого N структура будет отличаться тем, что "серых" вершин, кроме как на левой и верхней границах соответствующего рисунка, больше не будет вообще.
В случае же N=2 у нас будут только 3 сложения и одно вычитание, так что использование двойки в качестве базового сомножителя БПФ несёт несомненные выгоды.
Структура классического ДПФ в целом настолько проста, что её можно записать с помощью такой простой фортран-подпрограммы:
subroutine ft(f,a,w,N)
с
c параметры выбраны с теми же идентификаторами, что используются в постановке задачи
c w - массив множителей (нулевой не хранится, так как он равен 1)
с
complex f(0:N-1),a(0:N-1),w(N-1)
DO 10 i = 0, N-1
10 a (i) = f (0)
c
c инициализация сумм
c
DO 20 j = 1, N-1
20 a (0) = a (0) + f (j)
c
c вычисление нулевого элемента использует в качестве множителей только 1
с
DO 30 i = 1, N-1
DO 30 j = 1, N-1
jj = MOD (i*j, N)
c
c вычисление номера комплексного множителя
c
if (jj .eq. 0) then
a (i) = a (i) + f (j)
c
c умножать на 1 не нужно
c
else if (2*jj .eq. N) then
a (i) = a (i) - f (j)
c
c на -1 умножать тоже не нужно
c
else
a (i) = a(i) + f (j) * w (jj)
end if
30 CONTINUE
RETURN
END
(программа записана в нотации Фортрана 77).
Случай составного N
Рассмотрим случай N = p1 p2, причём сомножители не равны 1. Тогда, представим индексы элементов векторов и матрицы q, j в виде
(0 ≤ j1, q1 < p1, 0 ≤ j2, q2 < p2)
и подставим их в исходную формулу для элемента искомого вектора. Тогда после несложных арифметических преобразований, учитывая то, что
и то, что мнимая экспонента периодична с периодом 2π, получим, что
где
При вычислении по представленному алгоритму требуется всего
арифметических операций. В случае, когда сомножители равны друг другу, общее количество операций составит
Описанный алгоритм и носит название "Быстрое преобразование Фурье".
Сведение преобразования Фурье к последовательности преобразований меньшей размерности
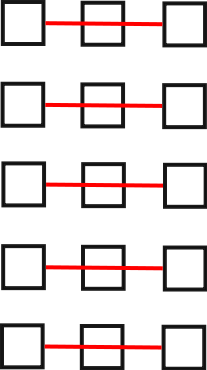
Приведённые выше формулы показывают интересную вещь. Оказывается, если записать исходный вектор f по столбцам прямоугольной таблицы размера p2 на p1, то его преобразование Фурье в вектор a может быть выполнено в следующие три действия (на рисунках-примерах мы будем считать, что исходная размерность равна 15):
- Вычисление преобразований Фурье порядка p1всех
строк
таблицы (красным на рисунке показаны группы элементов массива, над
которыми выполняются ДПФ размерности p1=3).
- Умножение элементов полученной таблицы на т.н. поворачивающие
множители (серым на рисунке показаны элементы массива, которые не нужно
умножать, разными цветами - умножаемые на разные поворотные множители;
как мы видим, часть поворачивающих множителей повторяется).

- Вычисление преобразований Фурье порядка p2
всех
столбцов таблицы (красным на рисунке показаны группы элементов массива,
над которыми выполняются ДПФ размерности p2=5).
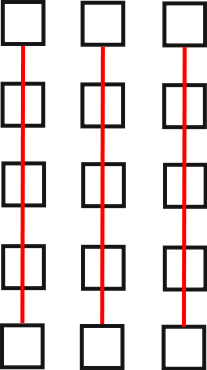
Искомый вектор a будет в получившейся таблице записан по строкам. Если же мы хотим, чтобы он тоже был записан по столбцам, как и исходный, то нам надо будет добавить четвёртое действие - транспонирование таблицы.
Указанная особенность - основными действиями являются те же преобразования Фурье, но меньшей размерности - позволяет применить приём БПФ и к ним, в том случае, если сомножители, образующие составное N, сами окажутся составными. Разработано много программ, которые доводят разложение до простых делителей числа N. Их детальный разбор можно прочитать, например в известной книге Блейхута. Самые известные из них, однако, получаются в следующем частном случае.
Размерность - степень двойки
Пусть N = 2k. Тогда вышеизложенную схему сведения преобразования Фурье к преобразованиям меньшей размерности можно выполнить особенно эффективно. Этому способствуют следующие причины:
- При выполнении преобразования размерности 2 вычисляемые экспоненты равны ±1, что дополнительно экономит на операциях умножения, оставляя только сложения и вычитания.
- Поворачивающие множители первого шага дают нам полный набор множителей второго и последующих шагов, что также даёт нам экономию (хоть и меньшего порядка, чем главные преобразования) в вычислениях как тригонометрических функций, так и комплексных произведений. О влиянии этого на ошибки округления в ДПФ будет сказано отдельно. При этом не равны 1 только множители второго столбца.
Общая структура одного шага БПФ (без учёта
транспонирований, но с учётом умножений на поворачивающие множители)
для N = 2k даёт нам рисунок такого вида:
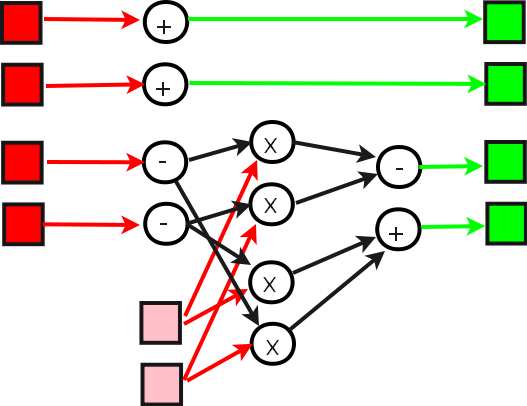
Красными линиями обозначена передача начальных данных (массива из
2+1 пар действительных чисел, каждая пара - действительная и мнимая
часть
соответствующих комплексных чисел). Далее мы вверху видим простую
запись результатов, а внизу - структуру с умножением на поворачивающий
множитель, не равный 1. Зелёными стрелками обозначена
запись данных в массив (и здесь мы видим в середине структуру,
заменившую транспонирование матрицы 2х2). Квадратами же обозначены
элементы массива (красными - начальные данные шага БПФ, зелёными -
вычисленное подпрограммой их ДПФ с умножением на множители, розовыми -
поворачивающий множитель).
Приведём теперь общую вычислительную структуру,
характерную для случая, когда размерность ДПФ - степень двойки. Даже
при последовательно-рекуррентной организации разбиения N пополам на ДПФ
меньшей размерности уже есть два варианта, описанных у Блейхута
(когда двойкой является количество строк в разбиении
выше, а дальнейшему разбиению пополам подвергаются столбцы, или же
наоборот, двойка - количество столбцов, а дальше разбиваются строки),
имеющие общепринятые для "сигнальщиков" названия - "с прореживанием по
частоте" или же "с прореживанием по времени" . Они, однако, близки по
структуре друг к другу:
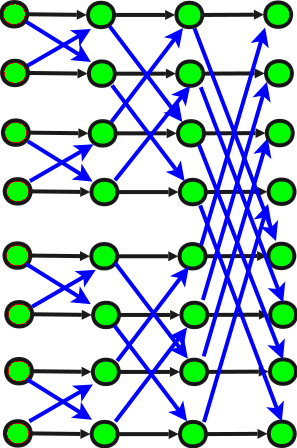
На рисунке - общая структурная схема БПФ для N=16. Зелёные вершины соответствуют выполняемым макрооперациям, описанным выше. Передача данных показана чёрными и синими стрелками. Ярусы параллельной формы макрографа БПФ расположены по вертикалям. Если всё делать таким образом, при выполнении БПФ для N = 2k известно, что оно может быть реализовано за N log2N / 2 операций комплексного умножения и N log2N операций комплексного сложения.
Здесь мы специально не приводим оценки через действительные умножения и сложения, поскольку для самих комплексных умножений есть разные реализации - как обычная (через 4 умножения и 2 сложения), так и "быстрая" (через 3 умножения и 3 сложения).
Как видно из рисунка, структура пересылок нелинейная, она экспоненциально зависит от номера шага БПФ. Однако при правильной организации сочетания транспонирований структура пересылок будет неизменной от шага к шагу БПФ. Платой за это будет, однако, то, что половина дуг будет принадлежать к классу длинных, т.е. передача данных не будет локальной, а также то, что предварительно данные надо будет расположить в так называемом битинверсивном порядке (то есть в таком, где двоичное представление индекса массива идёт наоборот). Эта подзадача (начальной пересортировки) занимает примерно N пересылок данных, но сложна логически, поэтому её решение мы здесь приводить не будем.
Для реализации на ПЛИСах есть пример фрагмента программы на языке Colamo, использующей БПФ (метод Кули-Тьюки для произвольной степени двойки) прямоугольного массива размера 1024х1024 по строкам, разработанный в НИИ МВС при ТРТУ. Вот её текст (мы будем периодически вставлять свои пояснения):
Include MyLibNewElement;
var ReX_in, ImX_in, ReX_out, ImX_out: Array real [1024:Stream, 1024:Stream] Mem;
// Входной и выходной массив строки, столбцы
var ReX_in_com, ImX_in_com: Array real [1024:Stream, 1024:Stream, 10: Stream] Com;
// Входной и выходной массив строки, столбцы, итерации
var invert: Array integer [10: Stream,512: Stream] mem;
// массив с адресами в битинверсивном порядке
Видно, что данные изначально уже расположены в так называемом битинверсивном порядке, так что разработчики программы для ПЛИС сложную логику этого переупорядочивания массива оставили для работы на внешнем хост-компьютере перед вызовом ПЛИС-модуля.
var N,i,j,k,m,p : Number;
var ReImW : Array real [512:Stream] Mem;
// массив коэффициентов БПФ
var ReA_reg, ImA_reg, ReB_reg, ImB_reg : real Reg;
// массив коэффициентов БПФ
var ReA_com, ImA_com, ReB_com, ImB_com : real com;
// массив коэффициентов БПФ
Здесь видно, что и вычисление тригонометрии тоже оставлено на предварительную работу хост-компьютера.
Define N=1024;
ReadFile (inv, FF_Int_64, "inv.txt");
// чтение из файла массива с адресами в битинверсивном порядке
ReadFile (ReImW, FF_Int_64, "ReImW.txt");
// чтение из файла массива коэффициентов
ReadFile (AB, FF_Int_64, "In_com.txt");
// чтение из файла массива коэффициентов
Начало описания структуры основной операции (так называемая "бабочка" БПФ):
let But_FFT(in: ReA, ImA, ReB, ImB, ReW, ImW;
// входные данные
out: ReA_out, ImA_out, ReB_out, ImB_out);
// выходные данные
var ReA, ImA, ReB, ImB, ReA_out, ImA_out, ReB_out, ImB_out, ReW, ImW: real com;
var Re_C, Im_C: real com;
// Массив коммут. переменных соотв. структуре БПФ
var mul_1, mul_2, mul_3, mul_4: real com;
// Массив коммут. переменных соотв. структуре БПФ
ReA_out := ReA + ReB;
ImA_out := ImA + ImB;
Re_C := ReA - ReB;
Im_C := ImA - ImB;
Mul_1 := Re_C*ReW;
Mul_2 := Im_C*ImW;
Mul_3 := Im_C*ReW;
Mul_4 := Re_C*ImW;
ReB_out := Mul_1 - Mul_2;
ImB_out := Mul_3 + Mul_4;
EndLet;
Видно, что ключевая структура But_FFT реализует именно структуру одного шага БПФ, которую мы видели выше. Далее следует БПФ строк изображения:
CADR Gor_FFT;
// Кадр вычисления спектра строк излбражения
for m := 0 to 2 do
begin
if m = 0 then
// передача входных данных com - переменным
begin
for i := 0 to 1024 - 1 do
// цикл по строкам
begin
for j := 0 to 1024 - 1 do
// цикл по строкам
begin
ReX_in_com[i, j, 0] := ReX_in[i, j];
ImX_in_com[i, j, 0] := ImX_in[i, j];
end;
end;
end
Здесь видно, что данные и результаты вычислений будут разнесены по итерациям в "фиктивном" массиве (который на самом деле не является массивом, поскольку имеет коммутационный тип, а только связывает операции друг с другом). Далее следует собственно основное гнездо циклов БПФ по строкам:
else if m = 1 then // "рабочая" итерация
begin
for i := 0 to 1024 - 1 do
// цикл по строкам
begin
for j := 0 to 10 - 1 do
// цикл по итерациям
begin
for k := 0 to 512 - 1 do
// цикл по Базовым операциям
begin
But_FFT(ReX_in_com[i,k*2,j], ImX_in_com[i,k*2,j], ReX_in_com[i,k*2+1,j], ImX_in_com[i,k*2+1,j],
// входные данные
ReImW[Invert[j,k]], ReImW[Invert[j,k]+1],
// коэффициенты
ReA_com, ImA_com, ReB_com, ImB_com);
// выходные данные
ReA_reg := ReA_com;
// передача выходного потока через регистры для того что бы избежать "кольца"
ImA_reg := ImA_com;
ReB_reg := ReB_com;
ImB_reg := ImB_com;
for p := 0 to 1 do begin
// цикл передачи выходных параметров
if p = 0 then begin
ReX_in_com[i,k,j+1] := ReA_reg;
ImX_in_com[i,k,j+1] := ImA_reg;
end
else if p = 1 then
begin
ReX_in_com[i,k+512,j+1] := ReB_reg;
ImX_in_com[i,k+512,j+1] := ImB_reg;
end;
end;
end;
end;
end;
end
Рассмотрим основное тело программы. Видно, что внутренний цикл (по k) реализует всё необходимое множество базовых "бабочек" на каждом шаге БПФ, выполняя при этом перетасовку данных для следующего шага. Структура индексов массивов, как видно, линейна, но имеет включённые константы, сопоставимые с половиной этой размерности массива. Охватывающий его цикл по j реализует шаги БПФ, а внешний цикл по i - перебор всех строк.Собственно, БПФ практически уже выполнено.
else if m = 2 then
// итерация передачи данных в выходное КРП
begin
for i := 0 to 1024 - 1 do
// цикл по строкам
begin
for j := 0 to 1024 - 1 do
// цикл по столбцам
begin
ReX_out[i, j] := ReX_in_com[i, j, 10];
ImX_out[i, j] := ImX_in_com[i, j, 10];
end;
end;
end;
end;
ENDCADR;
Этот маленький завершающий кусок выполняет запись результатов в реальные массивы из коммутационных. Оставшуюся часть программы мы здесь опустим, поскольку она не имеет отношения к собственно БПФ, а уже использует её результаты.
End_Program
Всё, как видим, программа не очень сложна. Отметим ещё раз важную вещь: несмотря на наличие в библиотеке MyLibNewElement тригонометрических функций, все массивы коэффициентов для этой программы должны быть предвычислены заранее. Связано это с двумя факторами. Во-первых, размер массива изображения фиксирован и повторять одну и туже работу нет нужды, в то время как поток изображений, обрабатываемых на ПЛИСах, может идти довольно большим потоком. Во-вторых, использование тригонометрических функций даже в случае одиночных вычислений нарушило бы равномерность загрузки элементов ПЛИС и, как следствие, привело бы к простою значительной части ПЛИС. Кроме того, отметим, что использование в вычислениях массива, казалось бы, десятикратно более объёмного, чем исходный, вовсе не увеличивает память, используемую в ПЛИС-модулях, поскольку коммутационный тип массива исключает его хранение там, где оно не необходимо.
Размерность - чётная степень двойки
Описанные выше схемы и программа БПФ для произвольной степени двойки являются той реализацией метода Кули-Тьюки, который наиболее распространён среди реализаций БПФ. Однако этот алгоритм, несмотря на его преимущества (например, однотипность основных операций на каждом шаге), не является самым быстрым из реализаций БПФ на степенях двойки. В случае, если k (показатель степени двойки) чётно, то оказывается, что БПФ методом Кули-Тьюки для N = 2k может быть реализовано даже за 3N log2 N / 8 операций комплексного умножения и N log2 N операций комплексного сложения. За счёт чего же чётная степень даёт нам дополнительный выигрыш?
Рассмотрим преобразование Фурье порядка 4. Применим к нему разложение на 2 БПФ порядка 2 и увидим, что все поворачивающие множители равны ±1 либо ±i, что даёт нам возможность не умножать соответствующие элементы таблицы, а просто брать их с разными знаками и комбинировать их действительные и мнимые части. Подпрограмму прямого БПФ порядка 4 набора 4 комплексных чисел можно на Фортране записать, например, так:
subroutine FT4D(A1,A2,A3,A4)
real
A1(2),A2(2),A3(2),A4(2),C1(2),C2(2),C3(2),C4(2)
C1(1) = A1(1)+A3(1)
C1(2) = A1(2)+A3(2)
C2(1) = A2(1)+A4(1)
C2(2) = A2(2)+A4(2)
C3(1) = A1(1)-A3(1)
C3(2) = A1(2)-A3(2)
C4(1) = A2(1)-A4(1)
C4(2) = A2(2)-A4(2)
A1(1) = C1(1)+C2(1)
A1(2) = C1(2)+C2(2)
A3(1) = C1(1)-C2(1)
A3(2) = C1(2)-C2(2)
A2(1) = C3(1)-C4(2)
A2(2) = C3(2)+C4(1)
A4(1) = C3(1)+C4(2)
A4(2) = C3(2)-C4(1)
return
end
А в обратном БПФ порядка 4 будут несколько переставлены знаки и индексы:
subroutine FT4R(A1,A2,A3,A4)
real
A1(2),A2(2),A3(2),A4(2),C1(2),C2(2),C3(2),C4(2)
C1(1) = A1(1)+A3(1)
C1(2) = A1(2)+A3(2)
C2(1) = A2(1)+A4(1)
C2(2) = A2(2)+A4(2)
C3(1) = A1(1)-A3(1)
C3(2) = A1(2)-A3(2)
C4(1) = A2(1)-A4(1)
C4(2) = A2(2)-A4(2)
A1(1) = C1(1)+C2(1)
A1(2) = C1(2)+C2(2)
A3(1) = C1(1)-C2(1)
A3(2) = C1(2)-C2(2)
A4(1) = C3(1)-C4(2)
A4(2) = C3(2)+C4(1)
A2(1) = C3(1)+C4(2)
A2(2) = C3(2)-C4(1)
return
end
Но его структура в принципе - та же. На рисунке
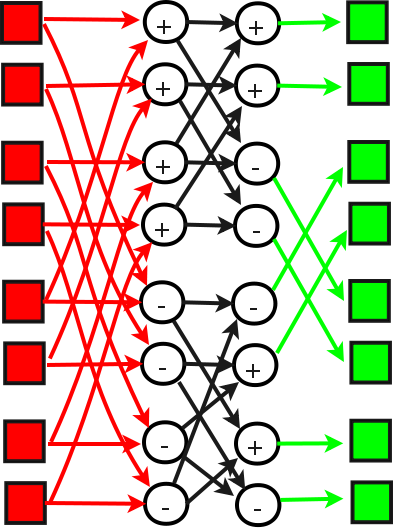
показана структура прямого преобразования Фурье размерности 4,
т.е. одно из элементарных преобразований БПФ порядка чётной степени
двойки. Красными линиями обозначена передача начальных данных (массива
из 4 пар действительных чисел, каждая пара - действительная и мнимая
часть соответствующих комплексных чисел). Далее мы вверху видим
структуру, похожую на шаг БПФ любой степени двойки, а внизу -
"запутанную" структуру похожего вида. Запутанность вызвана тем, что
умножение на поворачивающие множители было заменено расстановкой знаков
с взаимными заменами действительных и мнимых частей. Зелёными стрелками
обозначена запись данных в массив (и здесь мы видим в середине
структуру, заменившую транспонирование матрицы 2х2). Квадратами же
обозначены элементы массива (красными - начальные данные БПФ, зелёными
- вычисленное подпрограммой прямое ДПФ).
Теперь вспомним про умножение на поворачивающие множители, которое завершает шаг БПФ порядка, разложенного по четвёркам, и увидим, что из 4 полученных после Фурье порядка 4 комплексных чисел умножению подвергаются 3. То есть из всего массива - 3/4 2, в отличие от половины 2 в БПФ, разложенном по двойкам. Однако за счёт того, что самих шагов у нас вдвое меньше, мы и получаем выигрыш в множителе при N log2 N в количестве комплексных умножений.
Если мы попытаемся применить такой же приём для уменьшения доли комплексных умножений, например, взяв в качестве базового ДПФ порядка 8 (степень двойки, таким образом, должна делиться на 3), то увидим, что на поворачивающие множители умножаются 7 чисел из 8, полученных после ДПФ порядка 8, и за счёт того, что этапов втрое меньше - и получим, казалось бы, коэффициент 7/24, то есть ещё меньше. Однако в базовом ДПФ порядка 8, как оказывается, нельзя уже полностью избавиться от комплексных умножений, и при их учёте мы снова получаем те же, что для чётных степеней, 3/8 в коэффициенте при N log2 N. Правда, при ближайшем рассмотрении оказывается, что часть из умножений является умножением на числа специального вида и может быть выполнена быстрее, но это усложняет общую схему. Однако, если усложнение не пугает, то можно довести оптимизацию до размерности 16.
Общая схема БПФ чётной степени двойки, расписанная через макрооперации, выглядит ещё сложнее, чем без учёта чётности. Поэтому здесь она не приводится.
2На
самом деле - не 3/4 и не половина, а чуть меньше.
Размерности, не являющиеся степенями двойки
Реальные задачи таковы, что размерность ДПФ, которое подлежит
"убыстрению", может оказаться вовсе не степенью двойки. Для тех
специалистов, кто не хочет ломать голову над выбором алгоритма, в
настоящее время распространён метод решения "от степени", при котором
реальную задачу просто "подгоняют" под степень двойки (бывает даже, что
это делают с реальными АЦП в устройствах). Однако такой метод во многих
задачах неприемлем по разным причинам. Увеличение размера до ближайшей
степени двойки может существенно увеличить размер задачи. Кроме этого,
ряд задач традиционно ориентирован на размерности, заведомо не
являющиеся степенями двойки (хоть и содержащие их в качестве
делителей). Например, в геофизических климатических задачах одной из
традиционных сеток является градусная (или кратные градусной). При этом
получается, что размерность по долготе (с учётом периодичности) будет
кратна 360, то есть содержать одну пятёрку и две тройки. Поэтому
существуют такие алгоритмы БПФ, как
методы Гуда-Томаса, Винограда
и др. Надо сказать, что они, кроме прочего, являются и более быстрыми,
чем алгоритм Кули-Тьюки для произвольной степени двойки. Поэтому во
времена, когда ещё не было массовой компьютеризации и задачами БПФ
занимались только специалисты, в программах БПФ царило многообразие.
Ныне же большинство использует вовсе не самые быстрые БПФ, даже не
подозревая о том, что вобще можно работать не со степенями двойки.
Причём это связано не только с низким уровнем знаний о БПФ.
Особенности реализации БПФ на параллельных вычислительных системах
В случае, когда БПФ адаптируется для реализации на параллельной вычислительной системе (мы имеем в виду случай, когда нужно распараллеливать само преобразование Фурье, а не те алгоритмы, в которых преобразований Фурье разных векторов много и они сами могут выполняться параллельно или конвейерно), логическая сложность алгоритма, и, особенно, сложность деления данных по частям алгоритма, становится существенным тормозом для эффективной реализации. Кроме того, не секрет, что большинство многопроцессорных вычислительных систем с раздельной памятью (кластерная архитектура) часто предоставляет максимальное число узлов, являющееся степенью двойки. Системы, не имеющие таких ограничений, вроде ПЛИСов, имеют другие ограничения. Например, при программировании на COLAMO усложнение логической структуры при равной вычислительной мощности будет фактором, снижающим производительность базовых модулей, поскольку часть процессорных элементов при сложной логике программы будет либо простаивать, либо работать, но вхолостую (без использования результата). На кластерной архитектуре также, в случае разбиения схемы БПФ на блоки по процессорам, возникнут сложности, если разбивать придётся части схемы, реализующие ПФ меньшей размерности (разных делителей N). Всё это также приводит к тому, что реализации для степеней двойки вытесняют остальные алгоритмы БПФ.
К сожалению, нелинейная схема вызовов различных элементов рабочих массивов сказывается на различных реализациях БПФ порядка степени двойки, когда речь заходит об адаптации с минимизацией обменных операций (как на кластерах), либо при ограниченных ресурсах, выделенных на параллельную ветвь (как на ускорителях). При этом ряд разработчиков, сталкиваясь с тем, что все поворачивающие множители, предвычисленные им, не могут быть либо размещены в имеющейся памяти, либо быстро доставлены к месту их использования, идут на их перевычисление на каждом шаге. Это сразу сказывается на быстроте их реализаций, поскольку существенно увеличивает количество операций по сравнению с эталонным БПФ.
Более правильным шагом по преодолению ограниченности ресурсов либо минимизации пересылок, видимо, является использование такой схемы, которая заложена сама в БПФ, при её конструировании. Идея, в общем-то, настолько очевидная, что, когда у программиста есть полное разложение N на простые множители N=2k, она не всем приходит в голову: это использовать не полное разложение на простые множители, а разложение типа N=ML, где M, L - довольно большие числа, тоже являющиеся степенями двойки. Тогда мы видим, что все поворачивающие множители БПФ порядка N будут использованы только однажды - между БПФ порядка M и БПФ порядка L. Сами же эти БПФ порядков M, L можно, в зависимости от ресурсов, реализовать как БПФ степени двойки, либо тоже разложить на меньшие множители, и так - до той степени, пока ресурсов хватит, либо пересылок между компонентами МВС станет достаточно мало.
Ошибки округления и преобразование Фурье
Как нетрудно видеть по формулам, при выполнении преобразований Фурье большой размерности вероятно вычисление тригонометрических функций от больших аргументов. К сожалению, среди программ-реализаций преобразования Фурье автором было обнаружено сравнительно мало реализаций, выполняющих предварительное приведение аргумента с использованием целочисленной арифметики, а действительное приведение (используемое стандартными тригонометрическими функциями) даёт большую относительную ошибку. В самом деле, если порядок N и (следовательно) аргумента - 107, то его приведение к диапазону первого периода тригонометрических функций даст ошибку, на 32-разрядой арифметике (относительная точность которой 10-7) уже сравнимую с единицей, что делает преобразование неточным, а программу - ограниченно годной для небольших N.
В этом плане БПФ лучше традиционного преобразования Фурье (по той простой причине, что аргументы у функций существенно меньше, и поэтому программистские просчёты сказываются меньше), но и здесь резервы более точных вычислений используются редко. В лучшем случае эти резервы используются для предвычислений поворачивающих множителей друг через друга. Однако в случае размерности, равной целой степени двойки, оказывается, что и последнее ухищрение (предвычисление множителей) даст только дополнительные ошибки, в то время как применением простой сортировки с целочисленным приведением оно делается ненужным.
Заключение
БПФ традиционно относят к группе быстрых алгоритмов. Следует, однако, отметить, что многие быстрые алгоритмы, использующие ассоциативность и дистрибутивность умножений и сложений, являются неустойчивыми. На БПФ это не распространяется - как мы видим, даже при использовании тупого программирования без учёта особенностей тригонометрических функций влияние ошибок округления на БПФ меньше, чем на исходное преобразование Фурье.
К сожалению, неумелое программирование, встречающееся даже в кодах фирменной поддержки БПФ на различных ускорителях, приводит к тому, что преимущества БПФ с порядком вектора, равным степени двойки, в известной степени снижаются из-за того, что тригонометрические функции вычисляются на каждом шаге и потому неизбежно увеличивают коэффициенты количества операций при главном члене (N log2 N). Между тем, предварительное предвычисление всей нужной для ДПФ тригонометрии даёт возможность выполнить тригонометрию за O(N) операций, причём даже это предвычисление может быть в основном занято не вызовами тригонометрических функций, а комплексными умножениями, как хотя бы в примере программы, использующей формулы приведения для разбивания всего диапазона на 16 частей.
Также вызывает сожаление другое - редкое 3 использование разработчиками для современных параллельных вычислительных систем преимуществ чётной (а также кратной тройке и четвёрке) степени двойки. Схемы при этом получаются сложнее, но они не дают нам "холостых" ветвей и разбиений разной размерности. Поэтому разработчикам, желающим оптимизировать БПФ для степеней двойки, советуем обращать внимание на эту возможность.
3 Редкое - не то слово. Нам такие реализации просто не встречались.
© Лаборатория
Параллельных информационных технологий НИВЦ МГУ