Реализация на ПЛИС метода Гаусса для решения системы линейных алгебраических уравнений
Постановка задачи и математическая формулировка алгоритма
Рассмотрим систему линейных алгебраических уравнений (СЛАУ) относительно n неизвестных x1, x2, ..., xn. В матричной записи она имеет вид Ax=b, где A - квадратная матрица коэффициентов системы, x - вектор искомых неизвестных, b - вектор правых частей.
Под названием "метод Гаусса" существует целая группа методов решения этой задачи. Несколько методов основаны на разложении матрицы A в произведение двух треугольных матриц и, возможно, одной-двух матриц перестановок. При этом одновременно с разложением или после него может выполняться также преобразование правой части - вплоть до искомого решения. Желающие без труда найдут их описание в учебной литературе для студентов младших курсов.
Наличие в разложении матриц(ы) перестановок определено наличием в алгоритме выбора так называемого ведущего элемента, который потом оказывается на диагонали преобразуемой матрицы. Отчасти выбор этого элемента обусловлен желанием уменьшения влияния ошибок округления на решение задачи большой размерности, отчасти какой-то выбор необходим - без него даже СЛАУ с невырожденными матрицами могут быть не решены методом Гаусса без выбора ведущего элемента, для нерешаемости будет достаточно равенства нулю большой размерностиодного из главных миноров матрицы.
В даном случае речь пойдёт о реализации решения СЛАУ методом Гаусса с выбором ведущего элемента по столбцу без разложения матрицы. В этом методе расширенную матрицу системы [A|b] с помощью элементарных операций над строками матрицы сначала приводят к трапециевидному виду [U|u] (где U - верхняя треугольная матрица, u - промежуточный вектор), после чего обратным ходом метода Гаусса - к виду [E|x] (где E - единичная матрица).
При этом элементарными операциями здесь мы называем:
- перестановку строк;
- умножение строки на любое число, отличное от 0;
- сложение строки матрицы с другой строкой, умноженной на любое ненулевое число.
На рисунке 1 показана схема перестановки строк элементов расширенной матрицы после выбора ведущего элемента по первому столбцу. Синими и красным показаны элементы, среди которых производился выбор, красным - выбранный элемент (самый большой по абсолютной величине). Голубыми и розовыми показаны элементы двух переставляемых строк.
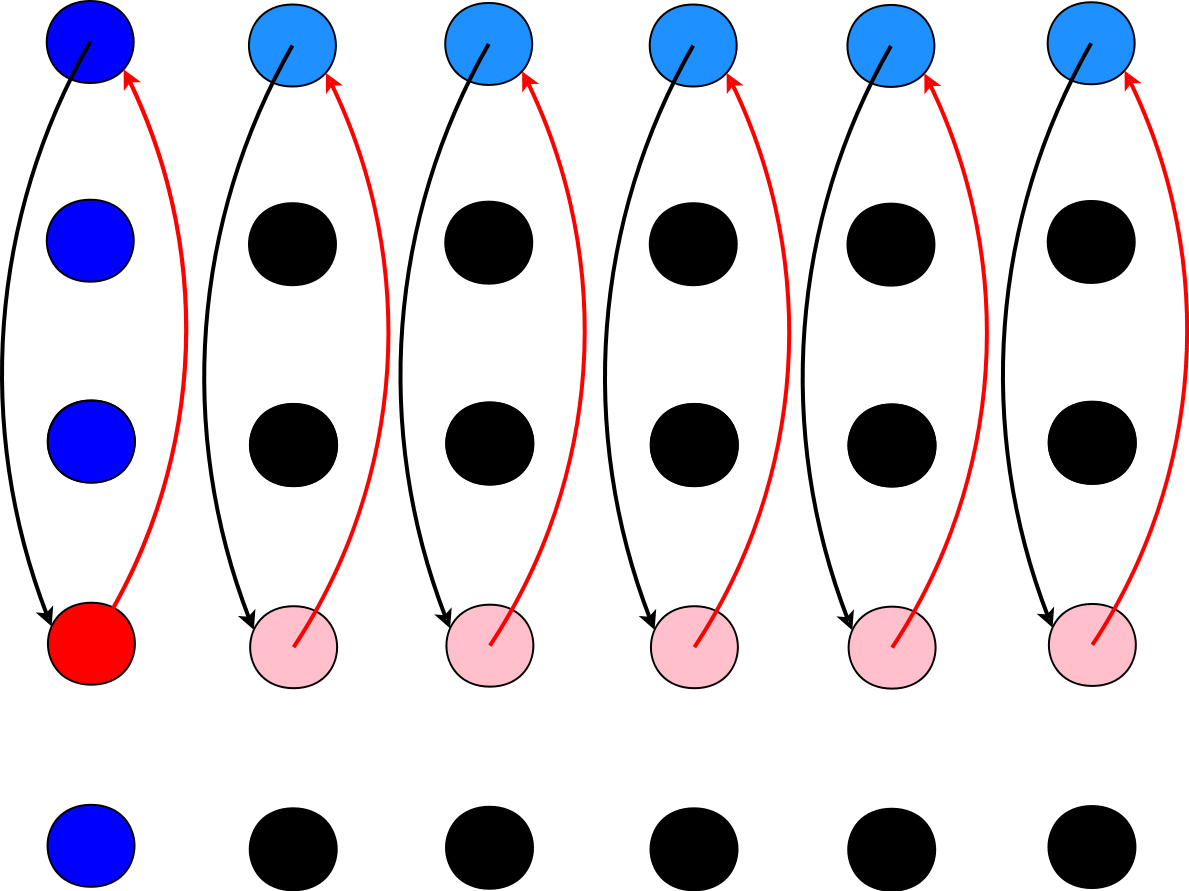
Рис.1 Перестановка строк элементов.
На рисунке 2 показана схема шага метода Гаусса, который выполняется после предыдущей перестановки строк. Ведущий элемент, который уже занял место в левом верхнем углу, отмечен красным цветом. Его значения передаются (см. красные дуги со стрелками) всему столбцу, отмеченному зелёным, где для каждой строки вычисляется свой коэффициент. Коэффициенты для каждой строки также рассылаются (зелёные пучки дуг) для перевычисления всех элементов соответствующей строки (синего цвета). Там они умножаются на полученные из первой (вые кружки и дуги) строки элементы и вычитаются из старых значений "синих" элементов. После завершения шага метода Гаусса следующие выбор ведущего элемента и шаг выполняются уже только для подматрицы, составленной из "синих" элементов, и так - до тех пор, пока "синих" элементов не останется одна, последняя строка.
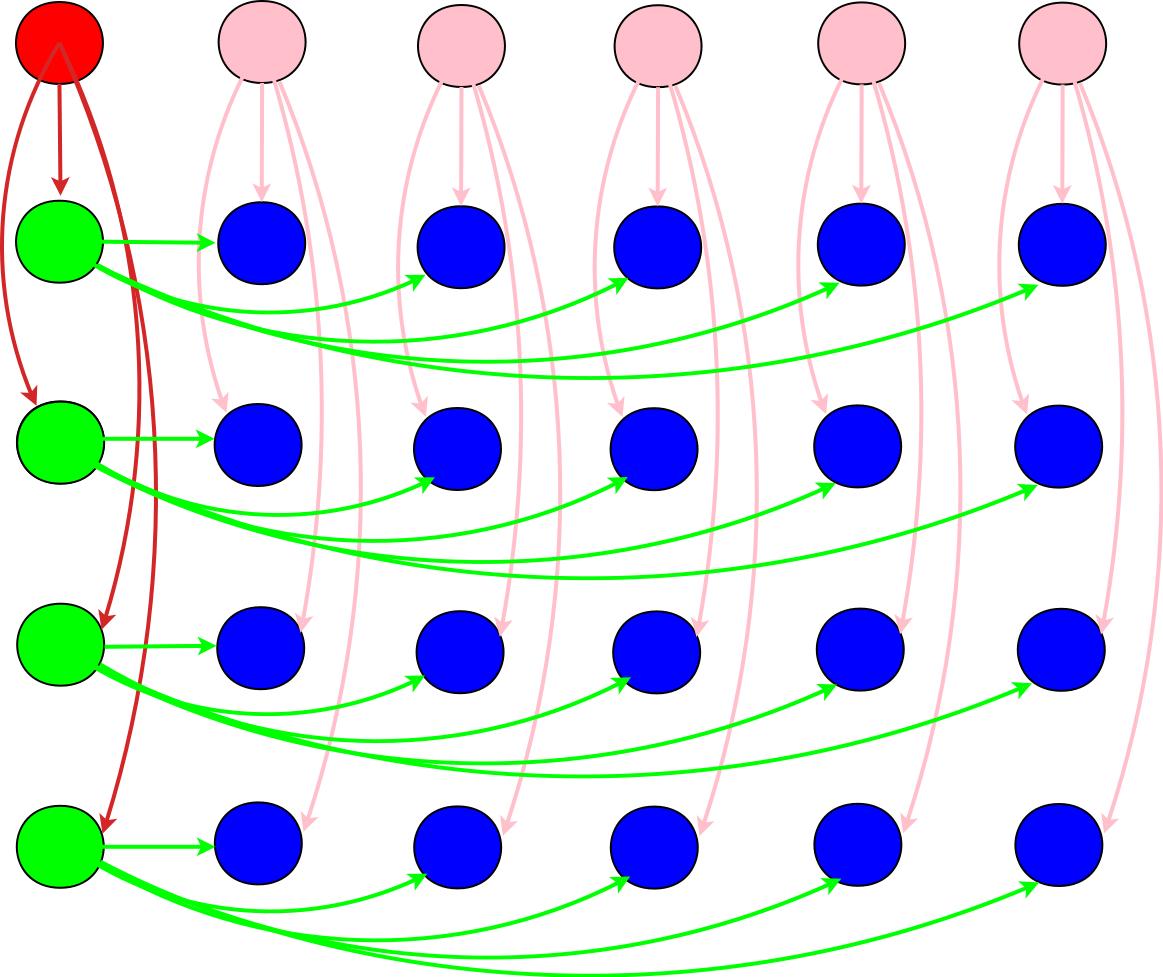
Рис.2 Шаг метода Гаусса.
После этого идёт обратный ход метода Гаусса. В описанной реализации на ПЛИСах выполняется и преобразование матрицы (возможно, для единообразности кадров), хотя, строго говоря, оно не нужно для получения искомого вектора. Поэтому схема почти та же самая, но проще за счёт отсутствия выбора ведущих элементов (они все уже лежат на диагонали матрицы).
Теоретические оценки времени решения задачи
Теоретически время решения СЛАУ методом Гаусса может быть оценено по следующей формуле:
- 2 - количество проходов алгоритма Гаусса (прямой и обратный);
- D - количество операций умножения-суммирования над элементами матрицы на одной итерации алгоритма;
- N - количество итераций (итерацией назовем выбор ведущей строки и соответствующая модификация ведомых строк).
- t - время выполнения одной операции умножения-суммирования.
Среднее количество операций умножения-суммирования над элементами матрицы на одной итерации рассчитывается в соответствии с формулой: D=n2/2, где n - размер стороны матрицы. Для матрицы размера n=104 время будет определяться как 1012 t.
При конвейерной реализации алгоритма на одном устройстве, выполняющем операцию умножения-суммирования, можно рассчитать общее время решения задачи. Пренебрегая временем заполнения конвейера и принимая, что одна операция выполняется за 1 такт на частоте 160 МГц, общее время будет равно около 104 мин. Частота 160 МГц выбрана как гарантированная частота обращения к микросхемам памяти.
Реализация алгоритма на персональном компьютере не позволяет организовать выдачу результата каждый такт. В связи с накладными расходами на организацию обращений к памяти, время выполнения одной операции увеличивается до нескольких тактов. Проведенный эксперимент показал, что время решения СЛАУ (n=104) на персональном компьютере составило 11.5 часов.
Параллельная реализация
Параллельная реализация предполагает обработку m строк m параллельно функционирующими устройствами одной ПЛИС. Так как размер матрицы равен n, то каждая из p ПЛИС базового модуля будет обрабатывать n/p строк. То есть, общее количество параллельно обрабатываемых строк будет равно mp строк (рисунок 3).
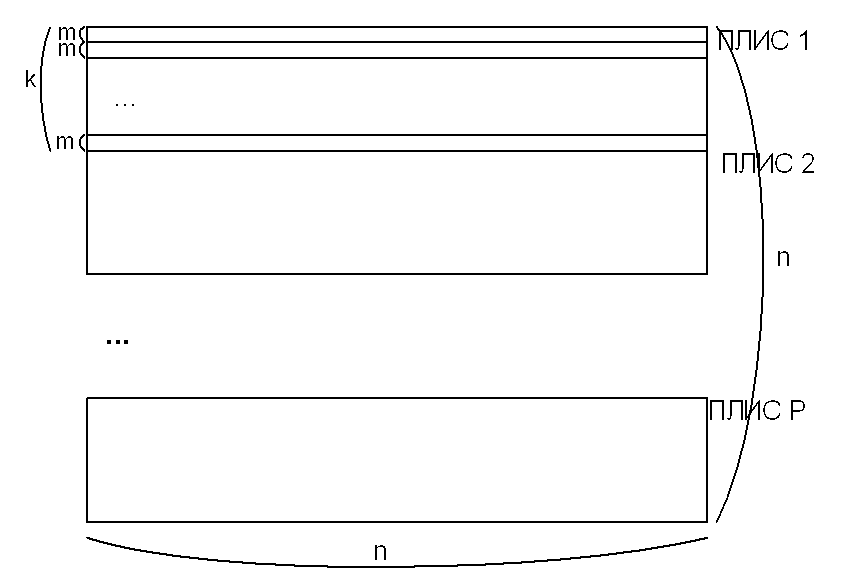
Рис.3 Параллельная реализация алгоритма.
Время решения задачи при параллельной реализации будет рассчитываться по следующей формуле:
В качестве наиболее эффективной ПЛИС по показателю стоимость/производительность на время реализации метода Гаусса являлась микросхема Xilinx семейства Vertex IV XC4VLX40. Ёмкости кристалла XC4VLX40 достаточно для реализации в нем 10 устройств умножения-суммирования элементов строк. Реализация алгоритма на плате базового модуля имеющего 16 корпусов XC4VLX40 позволит иметь 160 параллельно-функционирующих устройств. Время решения СЛАУ в этом случае составит: T = 1012t /160.
Если учесть, что одна операция выполняется за 1 такт на частоте 160 МГц, то общее время составит около 39 сек.
Однако, параллельная реализация 10 устройств требует наличия у каждой ПЛИС 10 входных и 10 выходных 32-битных каналов связи. Для организации одного 32-битного канала необходимо задействовать порядка 70 физических ножек ПЛИС. Для организации 20 входных/выходных каналов необходимо будет задействовать 1400 ножек. Корпусов ПЛИС имеющих 1400 пользовательских ножек не производится. Несмотря даже на это, процедура разводки и трассировки печатной платы для нескольких корпусов ПЛИС не позволила бы сохранить достаточно близкое расположение элементов друг от друга для сохранения необходимой частоты работы схемы.
Конвейерная реализация
В связи c невозможностью параллельной реализации алгоритма предлагается конвейерная реализация алгоритма решения СЛАУ. Представляется, что изначально массив строк исходной матрицы расположен во входной памяти. Вычислительного ресурса базового модуля достаточно для реализации m ступеней конвейера. Итерацией работы конвейерного алгоритма назовём выбор ведущей строки и соответствующую модификацию ведомых строк. Проходом алгоритма назовем m итераций. Количество проходов будет определяться как n/m. Конвейерная схема решения СЛАУ представлена на рисунке 4.
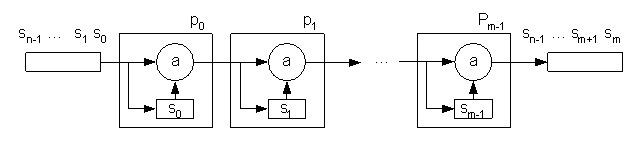
Рис.4 Конвейерная схема решения.
Ступень конвейера соответствует итерации алгоритма и функционирует следующим образом. При приходе первой строки она запоминается в буфер si. Для данной итерации эта строка является ведущей. Последующие строки минуют буфер si и попадают на блок "a", в котором модифицируются в соответствии с алгоритмом. По мере прихода строк на вход ступени конвейера, на выходе формируется последовательность обработанных строк, соответствующая очередной итерации алгоритма. На выходе последней ступени Pm-1 формируется последовательность строк, соответствующая проходу алгоритма. Эта последовательность запоминается в выходной памяти.
После прохода в буферах ступеней конвейера будут расположены обработанные m строк. Значения буферов должны быть выгружены в выходную память. Эти строки являются окончательно обработанными и в дальнейших проходах не участвуют.
Объём памяти, необходимый для реализации алгоритма, определяется как 2n2 слов, размер слова равен 4 байта. При n=104 объём памяти составит 800 МБ. При n=105 объём памяти составит 80 ГБ.
В соответствии с конвейерной реализацией время работы алгоритма будет
определяться в соответствии со следующей формулой:
Ресурса ПЛИС XC4VLX40 достаточно для реализации буферов памяти si для 5 ступеней конвейера. Таким образом, базовый модуль, состоящий из 16 ПЛИС и 1 ГБ памяти, позволит организовать цепочку из m=80 ступеней. Время решения задачи при n=104, m=80 и t=10-6/160 (160 МГц) будет составлять примерно 78 сек.
Краткие выводы
На примере реализации метода Гаусса решения СЛАУ на ПЛИСах мы видим, что при адаптации конкретного алгоритма на конкретной микросхеме важна не только его потенциальная (теоретическая) параллельность, но и согласованность потоков команд и данных с характеристиками микросхемы.
© Лаборатория Параллельных
информационных технологий НИВЦ МГУ