Классификация Дункана
В работе [20] Р.Дункан излагает свой взгляд на проблему классификации архитектур параллельных вычислительных систем, причем сразу определяет тот набор требований, на который, с его точки зрения, может опираться искомая классификация:
- Из класса параллельных машин должны быть исключены те, в которых
параллелизм заложен лишь на самом низком уровне, включая:
- конвейеризацию на этапе подготовки и выполнения команды (instruction pipelining), т.е. частичное перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение команды и сохранение результата;
- наличие в архитектуре нескольких функциональных устройств, работающих независимо, в частности, возможность параллельного выполнения логических и арифметических операций;
- наличие отдельных процессоров ввода/вывода, работающих независимо и параллельно с основными процессорами.
Причины исключения перечисленных выше особенностей автор объясняет следующим образом. Если рассматривать компьютеры, использующие только параллелизм низкого уровня, наравне со всеми остальными, то, во-первых, практически все существующие системы будут классифицированны как "параллельные" (что заведомо не будет позитивным фактором для классификации), и, во-вторых, такие машины будут плохо вписываться в любую модель или концепцию, отражающую параллелизм высокого уровня.
- Классификация должна быть согласованной с классификацией Флинна,
показавшей правильность выбора идеи потоков команд и данных.
- Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна, но, тем не менее, относятся к параллельным архитектурам (например, векторно-конвейерные).
Учитывая вышеизложенные требования, Дункан дает неформальное определение параллельной архитектуры, причем именно неформальность дала ему возможность включить в данный класс компьютеры, которые ранее не вписывались в систематику Флинна. Итак, параллельная архитектура - это такой способ организации вычислительной системы, при котором допускается, чтобы множество процессоров (простых или сложных) могло бы работать одновременно, взаимодействуя по мере надобности друг с другом. Следуя этому определению, все разнообразие параллельных архитектур Дункан систематизирует так, как показано на рисунке:
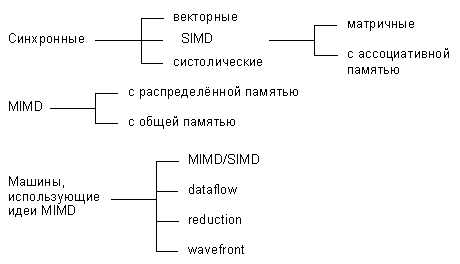
По существу систематика очень простая: процессоры системы работают либо синхронно, либо независимо друг от друга, либо в архитектуру системы заложена та или иная модификация идеи MIMD. На следующем уровне происходит детализация в рамках каждого из этих трех классов. Дадим небольшое пояснение лишь к тем из них, которые на сегодняшний день не столь широко известны.
Систолические архитектуры (их чаще называют систолическими массивами) представляют собой множество процессоров, объединенных регулярным образом (например, система WARP). Обращение к памяти может осуществляться только через определенные процессоры на границе массива. Выборка операндов из памяти и передача данных по массиву осуществляется в одном и том же темпе. Направление передачи данных между процессорами фиксировано. Каждый процессор за интервал времени выполняет небольшую инвариантную последовательность действий.
Гибридные MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы осуществляют параллельную обработку информации на основе асинхронного управления, как и MIMD системы. Но они выделены в отдельную группу, поскольку все имеют ряд специфических особенностей, которыми не обладают системы, традиционно относящиеся к MIMD.
MIMD/SIMD - типично гибридная архитектура. Она предполагает, что в MIMD системе можно выделить группу процессоров, представляющую собой подсистему, работающую в режиме SIMD (PASM, Non-Von). Такие системы отличаются относительной гибкостью, поскольку допускают реконфигурацию в соответствии с особенностями решаемой прикладной задачи.
Остальные три вида архитектур используют нетрадиционные модели вычислений. Dataflow используют модель, в которой команда может выполнятся сразу же, как только вычислены необходимые операнды. Таким образом, последовательность выполнения команд определяется зависимостью по данным, которая может быть выражена, например, в форме графа.
Модель вычислений, применяемая в reduction машинах иная и состоит в следующем: команда становится доступной для выполнения тогда и только тогда, когда результат ее работы требуется другой, доступной для выполнения, команде в качестве операнда.
Wavefront array архитектура объединяет в себе идею систолической обработки данных и модель вычислений, используемой в dataflow. В данной архитектуре процессоры объединяются в модули и фиксируются связи, по которым процессоры могут взаимодействовать друг с другом. Однако, в противоположность ритмичной работе систолических массивов, данная архитектура использует асинхронный механизм связи с подтверждением (handshaking), из-за чего "фронт волны" вычислений может менять свою форму по мере прохождения по всему множеству процессоров.
© Лаборатория Параллельных информационных технологий НИВЦ МГУ