Обзор архитектуры микропроцессоров Pentium Pro и Pentium II корпорации Intel
Александр Андреев (alexander@vvv.srcc.msu.su),
Лаборатория Параллельных Информационных Технологий НИВЦ МГУ,
3 ноября 1997 г.
Микропроцессоры Pentium Pro и Pentium II образуют шестое поколение микропроцессоров Intel. Оба микропроцессора поддерживают систему команд IA-32. Pentium II дополнительно поддерживает стандартную систему команд MMX для ускорения мультимедийных приложений.
Динамическое исполнение (Dynamic Execution)
Микропроцессоры Pentium Pro / Pentium II используют концепцию динамического исполнения (dynamic execution) для освобождения от ограничений традиционного последовательного исполнения инструкций. Эти процессоры поддерживают динамическое исполнение с помощью следующих механизмов:
- Улучшенное предсказание ветвлений (branch prediction)
- Переименование регистров (register renaming)
- Предваряющее исполнение (speculative execution) предсказанных ветвей кода
- Переупорядоченное исполнение (out-of-order execution) инструкций
Встроенная кэш-память первого уровня
Микропроцессоры Pentium Pro / Pentium II на
кристале содержат раздельные
модули кэш-памяти первого уровня (L1
cache) для данных и инструкций.
Размер каждого кэша равен 8K, длина
строки (cache line) составляет
32K. Ассоциативность равна для
кэша команд 4, для кэша данных - 2.
Оба кэша работают без блокировок;
это означает, что запрос к данным,
отсутствующим в кэше, не
задерживает последующие запросы.
Стратегии записи (Write policies)
Для различных областей (страниц) памяти могут быть установлены различные стратегии записи в эти области:
- Write Back - запись только в кэш
- Write Combining - запись в память через 32-байтовый буфер записи, соответствующий одной строке памяти
- Uncacheable - кэширование запрещено, запись только в память; используется для устройств В/B, отображаемых в память
- Write Through - запись в кэш и одновременно в основную память
- Write Protected - запись запрещена
Конвейерная архитектура
12-стадийный конвейер может быть поделен на три части слдеующим образом:
Последовательная подготовка к исполнению (In-order front-end)
- предсказание следуюшего значения указателя команд (IP)
- получение потока IA-инструкций из кэша команд; за один такт процессор считывает одну кэш-строку по адресу, записанному в IP
- декодирование инструкций в простые микрокооперации (micro-ops)
- переименование внешних IA-регистров для удаления зависимости по данным между микрооперациями
- назначение функциональных устройств и запись статуса микроопераций в буфере переупорядочения инструкций (ROB)
Переупорядоченное исполнение (Out-of-order execution)
- извлечение микроопераций, готовых к исполнению, из ROB и собственно исполнение
- временное сохранение результатов этих микроопераций в ROB
Последовательное завершение (In-order retirement)
- сохранение результатов во внешних IA-регистрах
- сохранение данных в памяти, если необходимо
- удаление завершенных микроопераций из ROB
Предсказание ветвлений
Микропроцессоры Pentium Pro / Pentium II используют два алгоритма для предсказания ветвлений, выбор между которыми происходит в зависимости от наличия информации об истории исполнения данной ветви.
Информация об исполнении инструкций условного перехода записывается в 512-строчной таблице Branch Target Buffer (BTB). Для каждой инструкции в BTB хранятся 4 бита, указывающие на наличие перехода в 4 предыдущих случая ее исполнения. При наличии такой информации, используется динамическим алгоритм предсказания ветвлений.
Если обнаружена инструкция условного перехода, для которой в BTB отсутствует история ее выполнения, используется статический алгоритм: для команд условного перехода назад предсказывается "переход", для команд условного перехода назад предсказывается "отсутствие перехода".
Для инструкций безусловного перехода (JMP) переход предсказывается в любом случае.
Декодирование инструкций
Процессор содержит три модуля декодирования инструкций IA в микрооперации; эти декодеры условно обозначаются D0, D1 и D2; все три декодера могут работать параллельно. При этом D0 может декодировать инструкции, порождающие до 4 микроопераций. D1 и D2 могут декодировать только инструкции, порождающие 1 микрооперацию. Если D0 декодирует сложную инструкцию (длиной более 7 байт или порождающую более 4 микроопераций), D1 и D2 одновременно работать не могут.
Функциональные устройства
Функциональные устройства, непосредственно выполняющие микро-операции в процессорах Penitum Pro и Pentium II, связаны с ROB посредством пяти портов.
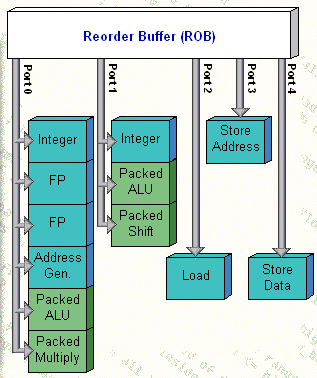 рис. 1
рис. 1
На рис. 1 показаны все функциональные устройства, вместе с соответствующими портами. Зеленым цветом выделены функциональные устройства, исполняющие MMX-операции и имеющиеся только в процессоре Pentium II.
Все порты и все функциональные устройства могут работать параллельно; однако за один такт каждый порт может использоваться только одним функциональным устройством.
© Лаборатория Параллельных информационных технологий НИВЦ МГУ