Nvidia Turing GPU
Паонкин А. В.,
ВМК МГУ,
Москва, 2018
1. Введение
Направление вычислений эволюционирует от «централизованной обработки данных» на центральном процессоре до «совместной обработки» на CPU и GPU. GPU обладает тясячами ядер, позволяя добиваться больших ускорений по сравнению с CPU на некоторых задачах.
NVIDIA GPUs следуют программной архитектуре SIMT (Single-Instruction, Multiple-Thread). NVIDIA GPU состоят из нескольких Streaming Multiprocessors(SMs), способных выполнять сотни потоков (threads) одновременно. Мультипроцессор создает, управляет, ставит в очередь и выполняет потоки группами по 32. Такие группы называются варпами (warps). Каждый поток в варпе начинает исполнение с одинакового программного адреса, но у них свои состояния регистров, счетчики адрессов и поэтому поток может осуществлять ветвление. Варп выполняет одну инструкцию за раз, поэтому максимальная эффективность достигается на участках кода без ветвления. Иначе каждая ветка исполняется по очереди, но всё же параллельно.
GPU позволяют достичь на некоторых задачах впечатляющих результатов, но существуют и принципиальные ограничения, не позволяющие этой технологии стать универсальной. Приведем лишь некоторые из них:
- Ускорить на GPU можно только хорошо параллелящийся по данным код. Одно ядро GPU "слабее" процессорного, GPU не обладает планировщиком для внеочередного исполнения команд.
- GPU использует собственную память. Передача данных между памятью GPU и оперативной памятью довольно затратна.
- Алгоритмы с большим количеством ветвлений работают на GPU неэффективно
2. Nvidia Turing
Nvidia Turing -- последняя на данный момент микроархитектура, разработанная компанией NVIDIA. Предыдущая архитектура Volta фокусировалась на ИИ и высокопроизводительных вычислениях, но большинство поддерживаемых архитектурой функций не были нужны в игровой индустрии. Например, отдельные блоки для арифметики с плавающей точкой. Turing же больше направлен на широкое потребление, чем на HPC. В семействе можно выделить несколько ключевых изменений: появление новых вычислительных блоков: тензорных и RT ядер, новая память и архитектура SM.
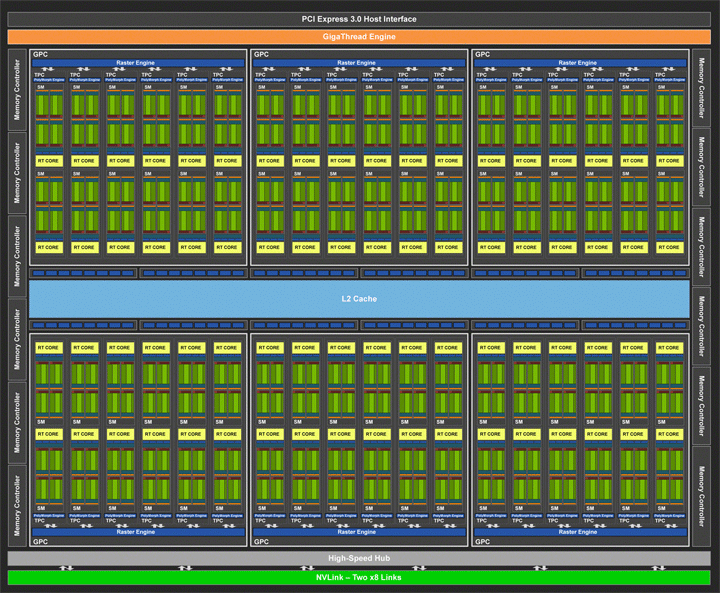
Рис. 1: TU102 -- GPU архитектуры Turing
Старший GPU TU102 в данной архитектуре содержит 6 Graphics Processing Clusters (GPC). Каждый кластер содержит блок растеризации и 6 TPC (Texture Processing Clusters), каждый TPC в свою очередь содержит 2 Streaming multiprocessors. В одном SM насчитывается 64 CUDA ядра. И теперь целочисленные операции (INT32) и операции с плавающей запятой (FP32) выполняются параллельно. Профилирование многих приложений на GPU показывает, что в среднем 36 целочисленных операций приходится на 100 с плавающей точкой. Каждый потоковый мультипроцессор также содержит 8 тензорных ядер для матричных вычислений, регистровые файлы размером 256 KB, 4 текстурных юнита(texture units), 96 KB L1/разделяемой памяти. Трассировка лучей выполняется с помощью новых специальных ядер (RT Cores).
Итак, TU102 GPU содержит:
- 4,608 CUDA ядер
- 72 RT ядер
- 576 тензорных ядер
- 288 текстурных юнитов
- 12 32-bit контроллеров памяти GDDR6
TU102 GPU включает 96 Rendering output units и 6144 KB L2 кэша.
Turing SM разбит на четыре блока, каждый с 16 FP32, 16 INT32 и 2 Тензорными ядрами, одним планировщиком(warp scheduler) и одним dispatch unit. Каждый блок включает новый L0 кэш инструкций и регистровый файл размером 64 KB. Четыре блока делят 96 KB кэша данных L1 /разделяемой памяти. Раньше кэшу данных отводилось 64 KB, разделяемой памяти -- 32 KB, теперь же распределение происходит динаминически(64/32 или 32/64) и зависит от вычислительной нагрузки.
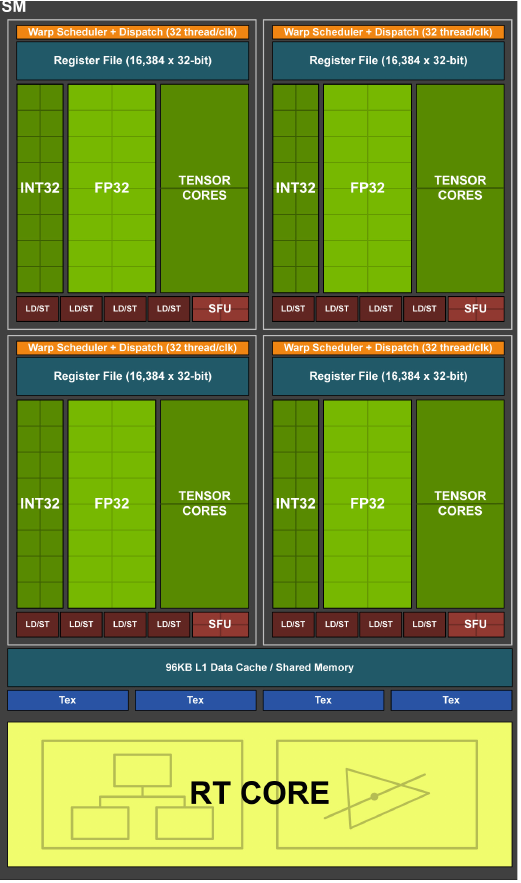
Рис. 2: Turing TU102/TU104/TU106 Streaming Multiprocessor (SM)
Тензорные ядра -- специальные вычислительные блоки для тензорных / матричных операций, являющимися ключевыми в области Глубокого Обучения. Дизайн тензорных ядер был улучшен по сравнению с архитектурой Volta GPUs. Самое главное изменение: добавлены новые режимы работы(INT8 и INT4).
Turing -- первая GPU архитектура, поддерживающая память GDDR6. GDDR6 достигает скорости 14 Gb/s и на 20\% энергоэффективнее по сравнению с памятью GDDR5X, используемой в Pascal GPUs.
3. Сравнение Turing с Pascal и Volta
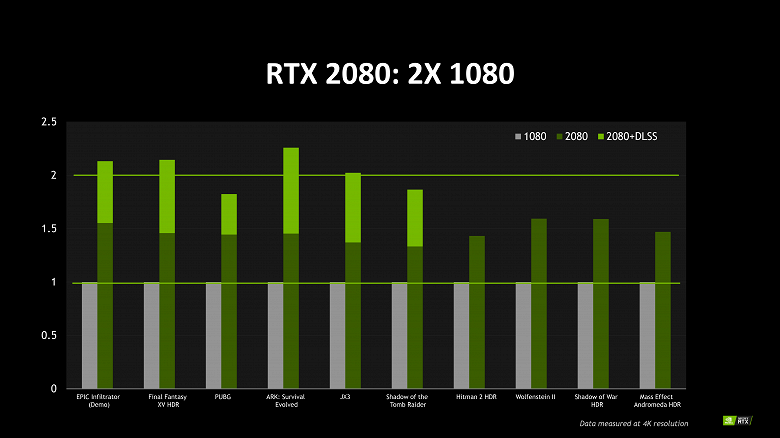
Рис. 3: Сравнение Turing RTX 2080 и Pascal GTX 1080
| GPU Architecture | Pascal | Volta | Turing |
| GPU Manufacturer | Nvidia | Nvidia | Nvidia |
| Fabrication Process | 14nm / 16nm | 12nm | 12nm |
| CUDA Cores | Yes | Yes | Yes |
| Tensor Cores | NA | Yes | Yes |
| RT Cores | NA | NA | Yes |
| Memory support | DDR4, GDDR5, GDDR5X, HBM2 | HBM2 | GDDR6 |
| VR Ready | Yes | Yes | Yes |
| VirtualLink (USB Type-C) | NA | NA | Yes |
| Multi-GPU support | Yes (in high end cards), SLI and NVLink | NVLink 2 | NVLink 2 / NVLink SLI |
| Graphics Cards | GeForce 10 series, Nvidia Titan X, Nvidia Titan Xp, Quadro P series workstation graphics cards, Quadro GP100 | Nvidia Titan V, Quadro GV100 | Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000 / RTX series graphics cards |
| Applications | Gaming, Workstation | Artificial Intelligence (AI), Workstation, Datacenter | Artificial Intelligence (AI), Workstation, Gaming |
| GPU | FP32 | FP16 |
| GTX 1080 Ti | 207 | NA |
| RTX 2080 | 207 | 332 |
| RTX 2080 Ti | 280 | 437 |
| Titan V | 299 | 547 |
4. Средства программирования
Наиболее известными инструментами создания программ, исполняемых на Turing GPU, являются расширения языков C и C++: OpenCL, CUDA, OpenACC. Первая библиотека полезна для создания программ, способных выполняться на различных конфигурациях из графических и центральных процессоров, а также FPGA. CUDA предназначен исключительно для Nvidia GPU, но предоставляет больше функций и традиционно быстрее программ, написанных на OpenCL, при исполнении на архитектурах NVIDIA. Программная архитектура OpenCL похожа на архитектуру CUDA, что позволяет переписать программу с одной платформы на другую.
Источники
- https://wccftech.com/review/nvidia-geforce-rtx-2080-ti-and-rtx-2080-review/2/
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
- https://habr.com/post/117021/
- https://www.ixbt.com/news/2018/08/22/nvidia-turing-pascal.html
- https://www.pugetsystems.com/labs/hpc/NVIDIA-RTX-2080-Ti-vs-2080-vs-1080-Ti-vs-Titan-V-TensorFlow-Performance-with-CUDA-10-0-1247/