Обзор графических ускорителей Nvidia P100 и Nvidia V100
Капридов А.,
ВМК МГУ,
Москва, 2018
1. Введение
Tesla P100 и Tesla V100 — графические ускорители компании Nvidia, специализирующиеся на задачах машинного обучения и супервычислений в области искусственного интеллекта[i]. Tesla P100 была представлена компанией в 2016 году, в то время как Tesla V100 была представлена годом позже — в 2017.
2. Обзор Nvidia Tesla P100
Существует 2 доступные конфигурации Tesla P100: с интерфейсом NVLink и интерфейсом PCIe. В конфигурации с NVlink[ii] на площади 610 мм2 расположено 15.3 миллиарда транзисторов и 3840 CUDA ядер распределенных между 60 потоковыми мультипроцессорами. Конфигурация с PCIe[iii] использует немного урезанную версию Tesla P100 с NVLink — в ней поместилось только 3584 CUDA ядер и частота GPU стала немного меньше, но все равно на момент выхода это было самое производительное решение в своем роде.
NVLink[iv] обеспечивает большую пропускную способность, чем PCIe за счет большего количества соединений и повышенной масштабируемости для конфигураций с несколькими GPU.
Меньшее количество CUDA ядер и уменьшенная частота GPU естественным образом сказалась на производительности Tesla P100 с PCIe. Более подробно различия в мощности представлены на таблице[v] ниже.
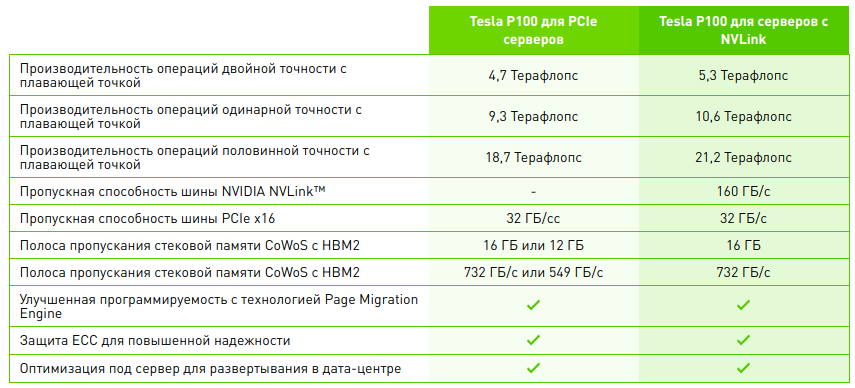
Таблица 1: Технические характеристики Nvidia Tesla P100
Помимо большой производительности Tesla P100 отличается еще и увеличенной пропускной способностью памяти благодаря подходу CoWoS. Его применяют для достижения большей плотности упаковки транзисторов на плате, что позволяет достичь большей производительности. Также версия с NVlink выгодно отличается от версии с PCIe как раз увеличенной пропускной способности шины NVlink, что тоже хорошо сказывается на производительности. И последнее, что можно сказать про память — это реализованная технология Page Migration Engine[vi], оптимизирующая работу с данными, превышающие физический объем памяти графического ускорителя путем добавления дополнительных виртуальных адресов обеспечивающих доступ к памяти системы и памяти всех GPU этой системы.
Tesla P100 стали первыми графическими ускорителями нацеленными конкретно на супервычисления в области искусственного интеллекта. Как раз для этих задач Nvidia активно использует особенности архитектуры Tesla P100, что позволяет им достигать еще большей производительности для таких задач.
3. Обзор Nvidia Tesla V100
Tesla V100 — следующее поколение высокопроизводительных графических ускорителей от Nvidia после Tesla P100. Благодаря переходу на 12 нм техпроцесс на чуть большую площадь, чем у Tesla P100 — 815 мм2 — удалось поместить 21 миллиард транзисторов, что на 6 миллиардов больше, чем у предшественника. Соответственно и CUDA ядер у Tesla V100 больше — 5120 против 2584 у Telsa P100. Конечно, количество транзисторов позволили достичь большей произволительности: 15.7 терафлопс на операциях с одинарной точностью для версии Tesla V100 с NVLink, более подробно характеристики представлены на рисунке ниже[vii].
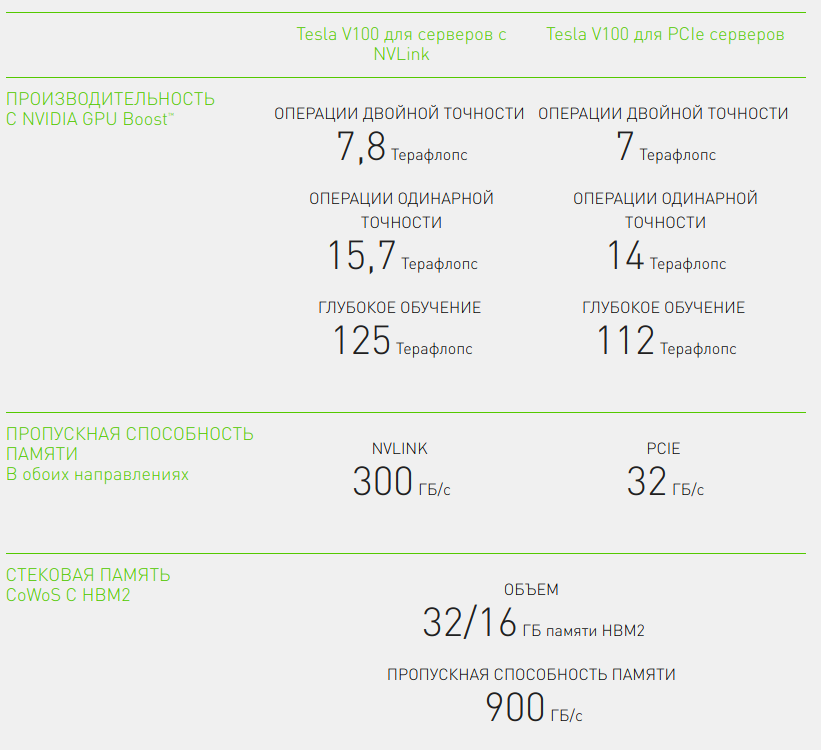
Рисунок 1: Технические характеристики Nvidia Tesla V100
Для Tesla V100 также доступны 2 модификации: с интерфейсом NVLink, и с интерфейсом PCIe. И точно также как и для Telsa P100 версия с PCIe незначительно проигрывает по производительности версии с NVLink, но несмотря на это версия с PCIe Tesla V100 почти в полтора раза превосходит Tesla P100 с NVLink по производительности.
Одним из главных отличий и нововведений Tesla V100 является наличие 640 тензорных ядер. Они специализируются на простых матричных перемножениях: если CUDA ядро вычисляет произведение двух чисел за один такт, то тензорное ядро за один такт производит перемножение двух матриц 4х4. Эти ядра имеют относительно небольшую сложность в реализации на транзисторах и занимают небольшую площадь на плате, но значительно повышают энергоэффективность при работе с обучением искусственного интеллекта.
Tesla V100 как представитель следующего поколения графических ускорителей Tesla тоже нацелена на высокопроизводительные вычисления в области искусственного интеллекта и обучении нейронных сетей. Но, благодаря улучшенной версии NVLink можно более продуктивно соединить несколько ускорителей, тем самым получив больший прирост производительности.
4. Сравнение Tesla P100 и Tesla V100 в задаче линейной алгебры
На следующем рисунке представлены графики производительности Tesla P100 и Tesla V100 на тесте cuBLAS[viii].
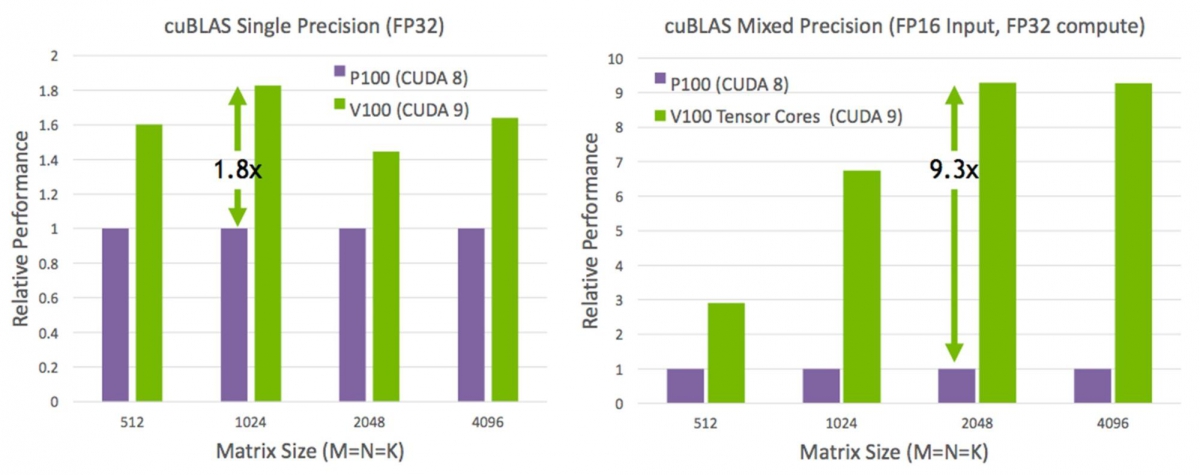
Рисунок 2: Сравнение Tesla P100 и Tesla V100 на тесте cuBLAS
Здесь явно заметны преимущества тензорных ядер у Tesla V100. Учитывая, что тензорные ядра как раз лучше всего приспособлены для перемножения матриц со смешанной точностью, неудивительно, что Tesla V100 производительней Tesla P100 до 9ти раз.
5. Сравнение Tesla P100 и Tesla V100 в задаче машинного обучения
Ниже представлены результаты сравнения производительности двух графических ускорителей в интерфейсом PCIe, проведенные независимыми разработчиками[ix].
Для этих тестов использовались версии Tesla P100 и Tesla V100 с интерфейсом PCIe установленные на почти идентичные системы, отличающиеся только размером оперативной памяти: 64 ГБ для Tesla P100 и 128 ГБ для Tesla V100. Тестирование проводилось с использованием технологии TensorFlow для рекуррентных нейронных сетей и для их модификации — рекуррентных сетей с долгой краткосрочной памятью. Каждый тип тестирования усреднялся по нескольким запускам.
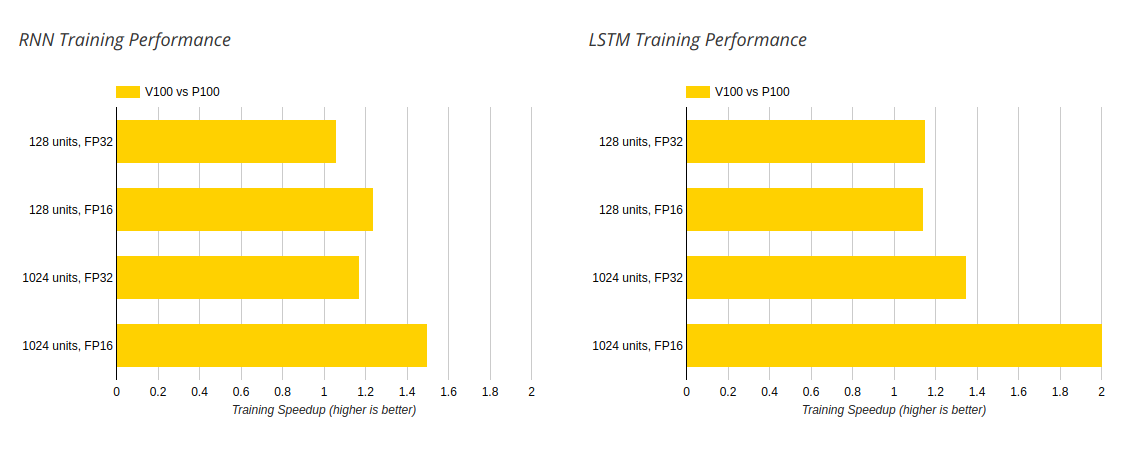
Рисунок 3: Сравнение Tesla P100 и Tesla V100 на задаче обучения
Исследователи приводят следующие данные ускорения Tesla V100 относительно Tesla P100 для обучения(trainig) и для предсказания(inference):
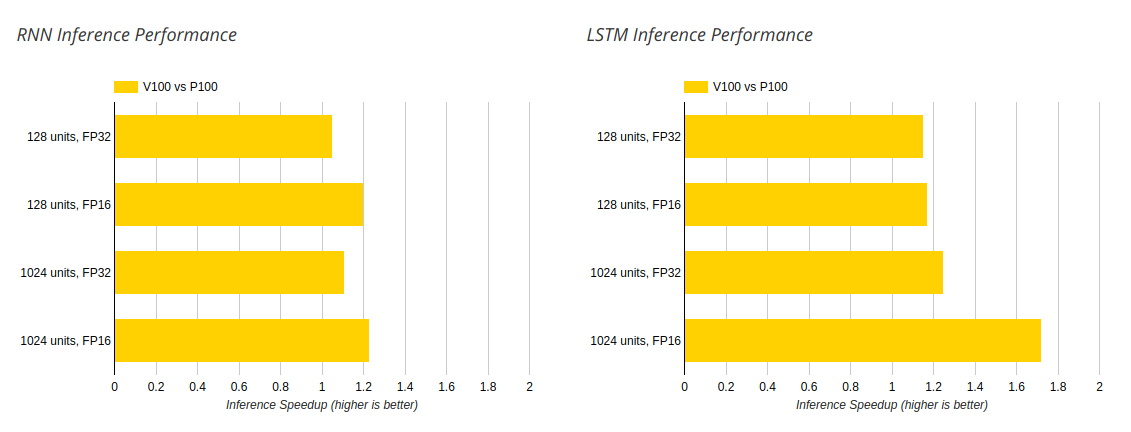
Рисунок 4: Сравнение Tesla P100 и Tesla V100 на задаче инференса
Как можно заметить TeslaV100 превосходит своего предшественника везде, но не во всех случаях эта разница сильно заметна. TeslaV100 лучше всего показывает себя при увеличении скрытых слоев сети и понижении точности вычислений. Особенно это заметно на обучении сетей с долгой краткосрочной памятью с половинной точностью и 1024 скрытыми слоями — в этом случае Tesla V100 справляется в 2 раза быстрее, чем Tesla P100. Скорее всего это заслуга новых тензорных ядер Tesla V100, которые как раз нацелены на относительно несложные матричные перемножения.
Однако, это был тест для всего одной видеокарты в каждом случае. В Nvidia же утверждают, что при соединении нескольких ускорителей можно достичь значительно большего ускорения, нежели с одной картой. Для демонстрации они приводят следующие данные:
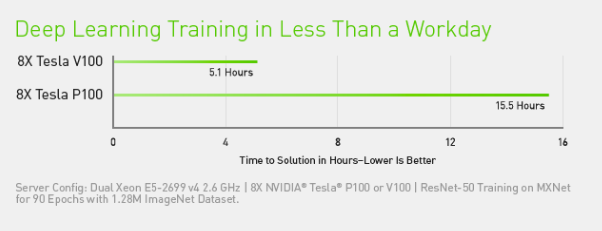
Рисунок 5: Сравнение производительности 8ми Tesla P100 и Tesla V100
Здесь мы видим уменьшение времени обучения на Tesla V100 в 3 раза. Наверняка, сыграл свою роль NVLink с увеличенной скоростью передачи данных между ускорителями.
6. Заключение
Оба графических ускорителя на момент выхода являлись самыми мощными в своей сфере. Да, Tesla V100 обгоняет своего предшественника по всем характеристикам, однако на практике разница заметна только на очень больших данных. Из этого можно сделать вывод, что обе карты все-таки предназначены для очень масштабных и дорогостоящих вычислений специализированных датацентров.
- [i] Обзорная статья с конференции GPU Technology Conference: https://habr.com/post/372057/
- [ii] Заметка о Tesla P100 с NVlink: https://www.ixbt.com/news/2016/04/05/gpu-nvidia-gp100-pascal-15.html
- [iii] Заметка о Tesla P100 с PCIe: https://www.ixbt.com/news/2016/06/20/nvidia-tesla-p100-pcie.html
- [iv] Страница NVLink нв сайте Nvidia: https://www.nvidia.com/ru-ru/data-center/nvlink/
- [v] Страница Tesla P100 на сайте Nvidia: https://www.nvidia.ru/object/tesla-p100-ru.html
- [vi] Информация о Page Migration Engine: https://devblogs.nvidia.com/beyond-gpu-memory-limits-unified-memory-pascal/
- [vii] Страница Tesla V100 на сайте Nvidia: https://www.nvidia.com/ru-ru/data-center/tesla-v100/
- [viii] Сравнение Tesla P100 и Tesla V100 на тесте cuBLAS: https://devblogs.nvidia.com/cuda-9-features-revealed/
- [ix] Сравнительные испытания Tesla P100 и Tesla V100: https://www.xcelerit.com/computing-benchmarks/insights/benchmarks-deep-learning-nvidia-p100-vs-v100-gpu/