Суперкомпьютер Trinity Cray XC40
Домрачева Д. А.,
ВМК МГУ,
Москва, 2018
Trinity – суперкомпьютер на базе суперкомпьютерной платформы Cray XC40, установленный в Лос-Аламосской национальной лаборатории (шт. Нью-Мексико, США). Введен в строй в 2015 году. Планируемое время работы – до 2020 года. На ноябрь 2018 года занимает 6-е место по производительности в мире в списке TOP500 с пиковой вычислительной мощностью в 41.5 PFLOPS [1]. Основное назначение суперкомпьютера – управление ядерным арсеналом США.
История создания
Декабрь 2013, Национальный научно-вычислительный центр энергетических исследований и Альянс крупномасштабных вычислений (ACES) выпустили совместный запрос на предложение с техническими требованиями для Trinity [1] .
- Июль 2014, компания Cray объявила о получении контракта от Национального управления по ядерной безопасности на 175 миллионов долларов с целью разработать следующее поколение суперкомпьютеров для Национальной лаборатории Лос-Аламос [2] .
- Июнь 2015, начинается установка узлов, основанных на процессорах Intel Xeon Haswell [3] .
- Ноябрь 2015, Trinity занимает шестое место в списке Top500 [4] .
- Июнь 2016, начинается установка узлов, основанных на процессорах Xeon Phi Knights Landing [5] .
- Ноябрь 2016, Trinity теряет позиции в списке Top500 и падает на десятое место [6] .
- Июль 2017, слияние узлов на процессорах базах Haswell и KNL [7] .
- Ноябрь 2018, Trinity вновь оказывается на шестом месте в списке Top500 за счет повышения реальной производительности с 14.1 до 20.15 PFLOPS [8] .
Основные цели создания
Суперкомпьютер Trinity был создан с целью предоставить увеличенный вычислительный потенциал для ядерного промышленного комплекса Национального управления по ядерной безопасности в связи с ростом требуемой геометрической и физической точности при симуляции использования ядерного оружия и поддержанием времени выполнения в разумных пределах. Способности Trinity необходимы для поддержки сертификации программы управления ядерным потенциалом и оценивания эффективности и безопасности программы.
Проект Trinity управляется Лос-Аламосской Национальной лабораторией, а также Национальной лабораторией Sandia, находящейся под контролем Альянса крупномасштабных вычислений (ACES). Вся система расположена в Nicholas Metropolis Center for Modeling and Simulation в Лос-Аламосе.
Технические характеристики Trinity [9]
|
Эксплуатационный период |
2015 — 2020 |
|
Архитектура |
Cray XC40 |
|
Память |
2.07 PiB[2] |
|
Пиковая производительность |
41.5 PFLOPS |
|
Количество вычислительных узлов |
19 420 |
|
Вместимость параллельной файловой системы |
78 PB[3] |
|
Вместимость пакетного буфера[4] |
3.7 PB |
|
Площадь |
428 м2 |
|
Энергопотребление |
8.6 MВт |
Вычислительная часть
Trinity был построен в два этапа. На первом этапе были подключены процессоры Intel Xeon Haswell, на втором этапе производительность была существенно увеличена за счёт процессоров Intel Xeon Phi Knights Landing. На данный момент насчитывается 301 952 процессоров Haswell и 678 912 процессоров Knights Landing в объединённой системе, что позволяет достичь пиковой производительности в 41.5 PFLOPS.
Производительность |
Intel Xeon Haswell E5-2698v3 [10] |
Intel Xeon Phi 7250 [11] |
|
Количество ядер |
16 |
68 |
|
Базовая тактовая частота процессора |
2,30 ГГц |
1,40 ГГц |
|
Максимальная тактовая частота с технологией Turbo Boost |
3,60 ГГц |
1,60 ГГц |
|
Кэш L1 |
64 KБ |
64 KБ |
|
Кэш L2 |
4 MБ |
34 MБ |
|
Кэш L3 |
40 MБ |
– |
|
Расчетная мощность |
135 Вт |
215 Вт |
|
Диапазон напряжения VID |
0.65В – 1.30В |
0.550В – 1.125В |
Вычислительные узлы [13]
Узел с процессором Intel Xeon Haswell
Каждый узел оборудован двумя процессорами Intel Xeon Haswell, в каждом из которых 16 ядер, имеющих доступ к четырем двусторонним модулям оперативной памяти (DDR4 DIMM – Double Data Rate four Dual In-line Memory Module). Между собой процессоры соединены двумя высокопроизводительными последовательными кэш-когерентными шинами QPI (Quick Path Interconnect). К сети узел подсоединен с помощью PCI Express 3 x16 (соединение типа «точка-точка»), скорость достигает 32 ГБ/с [14]. К контроллеру ввода-вывода (Southbridge Chip) подключен один из процессоров узла с помощью шины DMI2 (Direct Media Interface) [15].
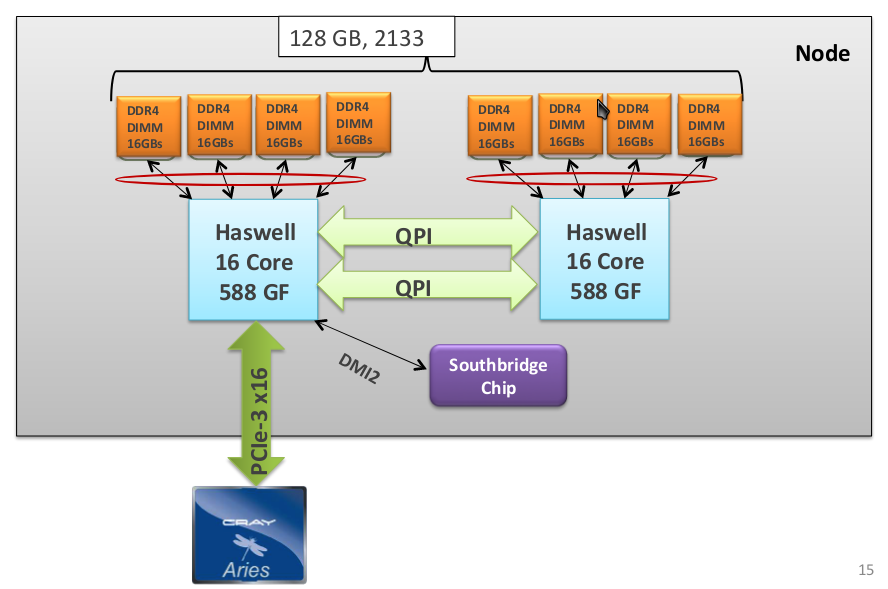
Рисунок 1: Узел на основе процессора Intel Xeon Haswell
Узел с процессором Intel Xeon Phi
Процессор Intel Xeon Phi подлкючен к оперативной памяти объемом 96 ГБ. К южному мосту процессор подключен с помощью шины DMI2, пропускная способность достигает 2 ГБ/c [16].
К сети узел, как и в случае Intel Xeon Haswell, подключается с помощью соединения PCI Express 3 x 16.
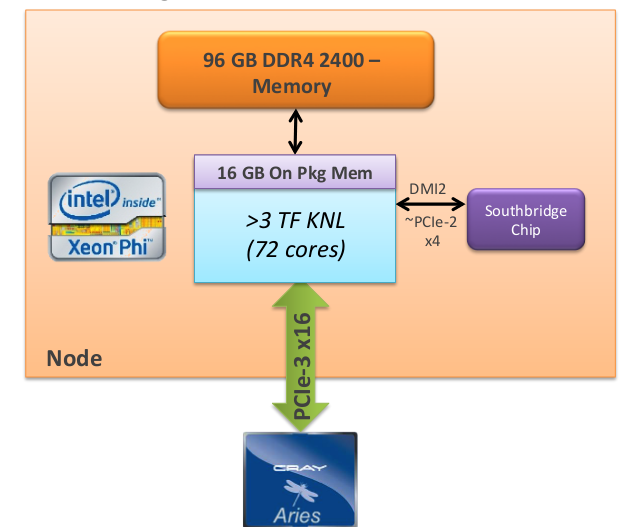
Рисунок 2: Узел на основе процессора Intel Xeon Phi
Файловая система MarFS
Файловая система MarFS входит в основное хранилище данных и объединяет в себе черты POSIX и моделей объектных хранилищ. В процессе тестирования ученые из Лос-Аламосской национальной лаборатории сумели создать 968 миллиардов файлов в одной директории, при этом приблизительная скорость создания файлов равнялась 835 миллионов файлов в секунду.
Система охлаждения
В суперкомпьютере представлена система охлаждения теплой водой. При этом в целях экономии используется не обычная проточная вода из системы городского водоснабжения, а вода из Sanitary Effluent Reclamation Facility (SERF), таким образом сохраняются десятки миллионов галлонов воды в год [17] .
Архитектура [18]
Trinity состоит из 9 436 узлов на оснве процессора Intel Xeon Haswell и более 9500 узлов на основе Intel Xeon Phi, соединяющихся с пакетным буфером объемом в 3.69 петабайт. Через медиашлюзы вычислительные узлы соединены с узлами предоставления доступа. С помощью роутеров Lustre и коммутаторов Infiniband вычислительные узлы соединены с файловой системой объемом в 78 петабайт.
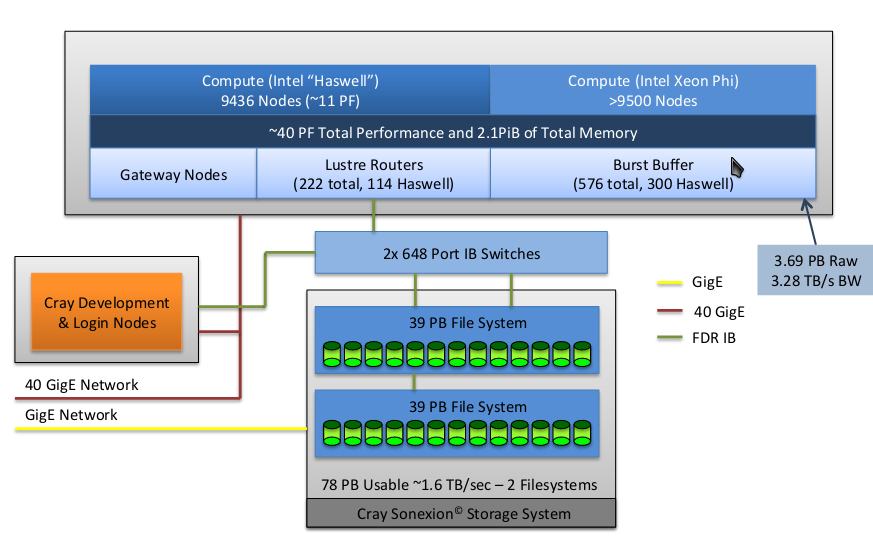
Рисунок 3: Архитектура Trinity Cray XC40
Программное обеспечение [19]
Языки программирования:
- Fortran
- C
- C++
- Python
- Chapel
Компиляторы:
- Cray Compiling Environment (CCE)
- Intel
- GNU
Модели программирования (для распределенной памяти):
- MPI: Cray Mpich & OpenMPI
- SHMEM
- OpenMP4.0
- PGAS & Global View
- UPC
- CAF
- Chapel
Библиотеки I/O:
- NetCDF
- HDF5
Инструменты отладки:
- DDT
- TotalView
- ATP
- STAT
- Cray Comparative Debugger
Дополнительные библиотеки:
- Libsci
- MKL
- LAPACK
- ScalAPACK
- BLAS
- Cray Adaptive FFTs
- Cray PETSc
- Cray Trilinos
- FFTW
Cray XC40
Cray XC40 —это суперкомпьютер с массово-параллельной архитектурой, используемый как в научных целях, так и в академических и промышленных областях.
Интерконнект Aries и топология «Стрекоза»
С целью сделать прорыв в производительности и масштабируемости, суперкомпьютеры серии Cray XC используют оптимизированный для высокопроизводительных вычислений интерконнект Aries. Эта инновационная технология сетевого взаимодействия реализована на топологии сети «Стрекоза» (Dragonfly), разработанной по итогам исследования, проведенного специалистами по сетям из Стэнфордского университета совместно с инженерами Cray [20] , с высокой пропускной способностью и небольшим диаметром сети (максимальное расстояние между двумя процессорами или скорость распространения сигнала, умноженная на время распространения сигнала), а также требующей меньше оптических каналов. Таким образом, Aries обеспечивает существенное улучшение метрик общей производительности сети: пропускной способности, задержки, скорости передачи сообщений и так далее. Этот способ организации сети предоставляет программистам глобальный доступ ко всей памяти параллельной программы и поддерживает самые востребованные коммуникационные шаблоны.
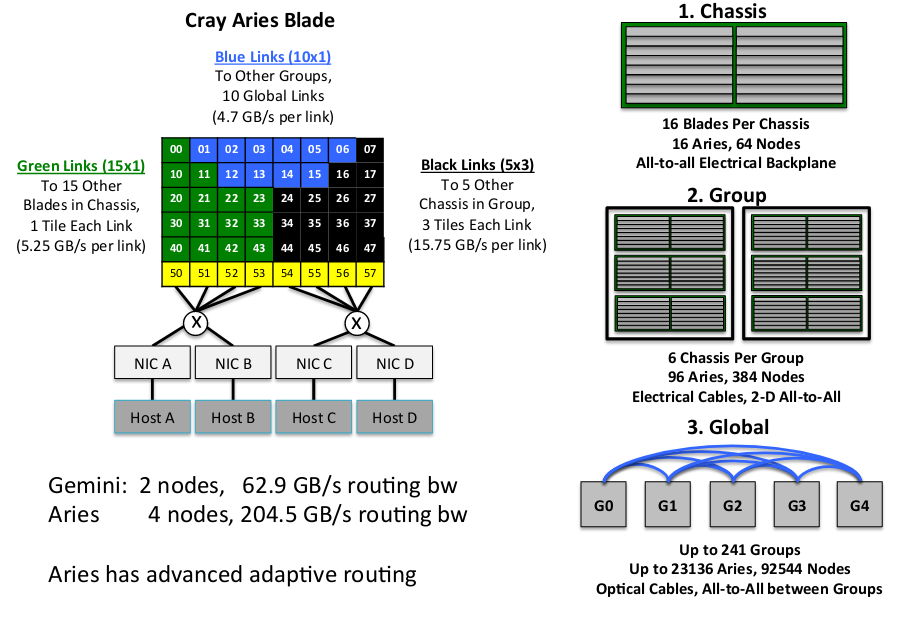
Рисунок 4: Интерконнект Aries
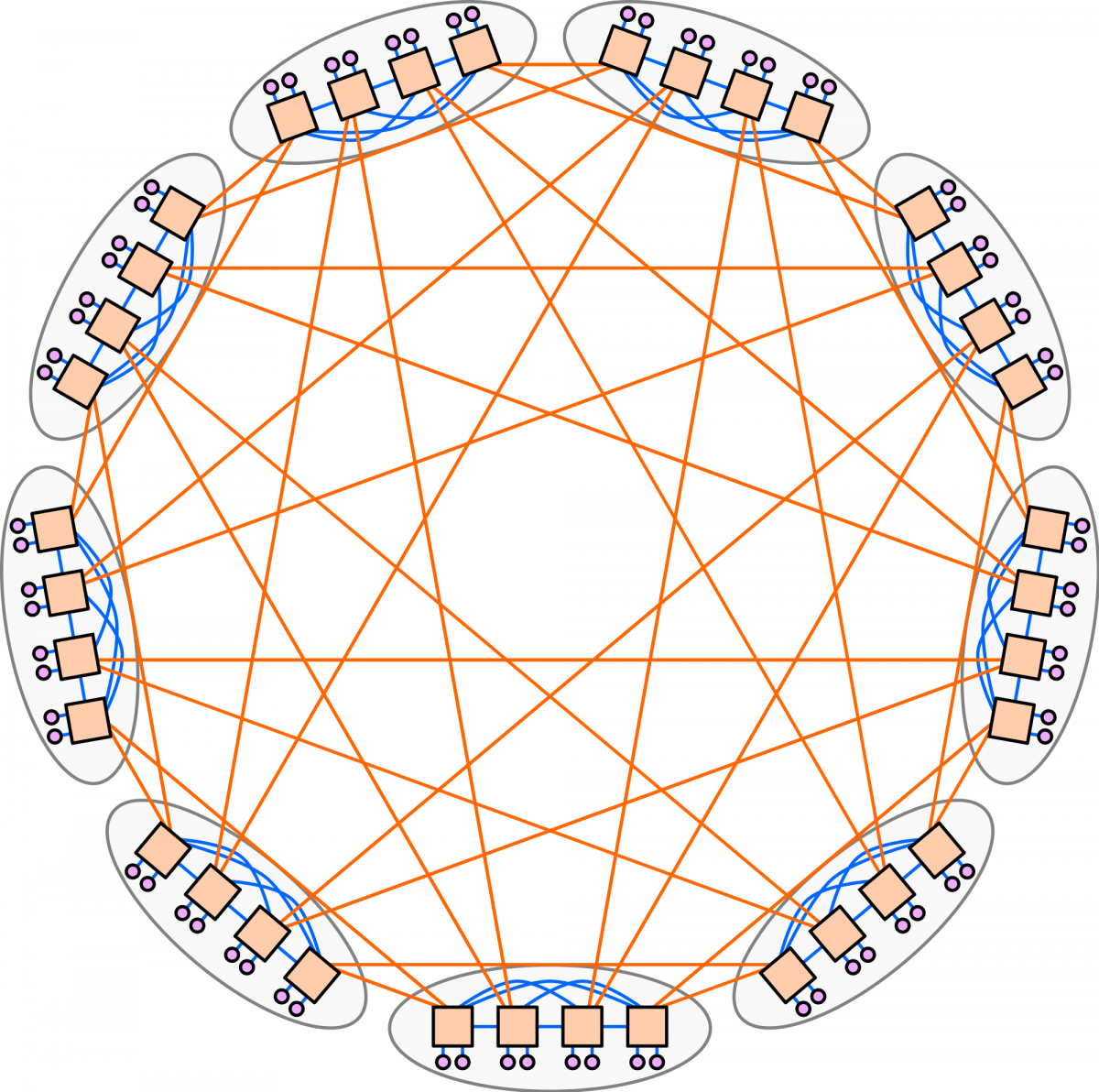
Рисунок 5: Топология Dragonfly
Список литературы:
[2] http://investors.cray.com/phoenix.zhtml?c=98390&p=irol-newsArticle&ID=1946457&highlight=
[3] https://www.hpcwire.com/2017/07/19/trinity-supercomputers-haswell-knl-partitions-merged/
[4] https://www.top500.org/lists/2015/11/
[5] https://insidehpc.com/2017/07/lanl-adds-capacity-trinity-supercomputer-stockpile-stewardship/
[6] https://www.top500.org/lists/2016/11/
[7] https://www.hpcwire.com/2017/07/19/trinity-supercomputers-haswell-knl-partitions-merged/
[8] https://www.top500.org/lists/2018/11/
[9] www.lanl.gov/projects/trinity/specifications.php
[10] ark.intel.com/ru/products/81060/Intel-Xeon-Processor-E5-2698-v3-40M-Cache-2-30-GHz-
[11] ark.intel.com/ru/products/94035/Intel-Xeon-Phi-Processor-7250-16GB-1-40-Ghz-68-core-
[12] On the role of burst buffers in leadership-class storage systems, April 2012 Ning Liu, Jason Cope, Philip Carns, Christopher Carothers, Robert Ross, Gary Grider, Adam Crume, Carlos Maltzahn
[13], [18], [19] Trinity Platform Introducton and Usage Model, ACES Team, August 2015
[14] www.ixbt.com/news/hard/index.shtml?14/03/51
[15] Scott Mueller, Upgrading and Repairing PCs, Que, 2013, page 188 "Hub Architecture"
[16] 2hpc.ru/шина-pci-express-x1-x2-x4-x8-x12-x16-x32/
[17] www.lanl.gov/asc/trinity-highlight.php
[20] Cray XC40 Scaling Across the Supercomputer Performance Spectrum, Cray Inc.
[1] PFLOPS – 1015 FLoating-point Operations Per Second (операций с плавающей запятой в секунду)
[2] PiB – Pebibyte, 1 pebibyte = 250 bytes
[3] PB – Petabytes, 1 petabyte = 1015 bytes
[4] Пакетный буфер (Burst Buffer) – быстродействующий и промежуточный уровень хранения, размещаемый между внешними вычислительными процессами и внутренними системами хранения [12]