Производительность SCI-кластера на процессорах Xeon
Здесь собраны данные по производительности 24-процессорного кластера на процессорах Xeon под условным названием "DWARF", полученные в сентябре-октябре 2003 года (сейчас этот кластер доступен пользователям НИВЦ МГУ под именем leo).
В некоторых случаях будет приведено сравнение результатов для нового кластера DWARF с результатами для кластера "SCI", собранного в 2000 году. Термин SCI здесь используется как название высокоскоростной сети и как название одного из двух кластеров.
Сравнительные характеристики кластеров SCI и DWARF
| Характеристика | SCI | DWARF |
|---|---|---|
| Процессор | Pentium III (Katmai) | Pentium 4 Xeon (система команд SSE2) |
| Тактовая частота процессора | 500 МГц | 2660 МГц |
| Кэш-память второго уровня (на каждом процессоре) | 512 Кбайт | 512 Кбайт |
| Процессоров на узле | 2 | 2 |
| Объем памяти на узле | 1 Гбайт (PC-100) | 1 Гбайт |
| Чипсет | Intel 440BX | Intel E7501 |
| Узлов в кластере | 18 (сейчас 16) | 12 |
| Частота системной шины (FSB) | 100 МГц | 533 МГц |
| Адаптеры SCI | D311/D312 (на шине PCI-32/33 МГц) | D335 (на шине PCI-64/66 МГц) |
| Топология сети SCI | 2D-тор 6x3 (сейчас 4x4) | 2D-тор 3x4 |
| Коммуникационное ПО | SSP 2.1 | SSP 3.1 |
Содержание
- Производительность процессоров.
- Производительность коммуникационной среды.
- Производительность на тесте LINPACK.
- Производительность на прикладных тестах.
Производительность процессоров
Какая достигается максимальная производительность одного процессора?
Производительность на реальных тестах в значительной степени зависит от используемого компилятора, а также от размера задачи. На тесте LINPACK с размером матрицы 100x100 (данные которого попадают в кэш-память второго уровня) при использовании компилятора Интел (ifc) была получена производительность в 1251 Мфлоп/сек. На других тестах была получена производительность порядка 2 Гфлоп/сек, что примерно соответствует выполнению 1 операции с плавающей точкой за такт.
На тесте LINPACK с максимально возможным размером матрицы (10000x10000) была получена производительность в 3164 Мфлоп/сек.
Как зависит производительность от используемого компилятора?
На следующей диаграмме приведены результаты производительности, полученные на простых процессорных тестах, при компиляции с помощью компиляторов GCC 2.96, GCC 3.3 и компиляторов Intel версии 7.1 (ifc/icc). Тесты LINPACK, LINPACK TPP и peak.f реализованы на Фортране, а все остальные - на Си.
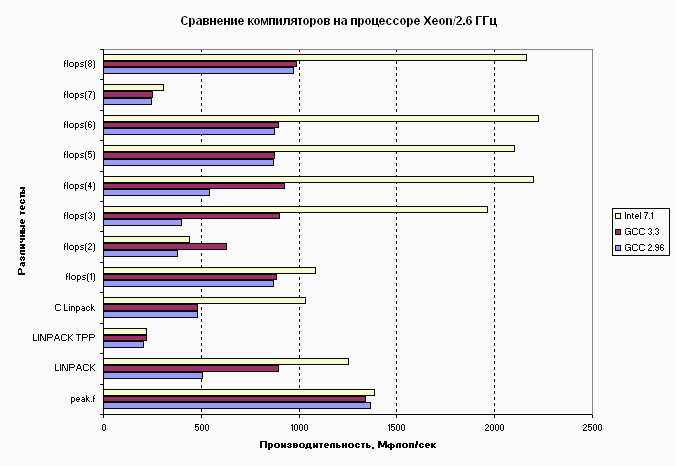
Производительность Xeon/2.6ГГц при использовании компиляторов GNU и Intel.
Здесь видно, что на некоторых тестах компиляторы Intel дают значительный выигрыш в производительности по сравнению с компиляторами GNU, причем версия GCC 3.3 несколько лучше по сравнению с GCC 2.96. При этом на задаче относительно большого размера - LINPACK TPP, данные которой полностью не помещаются в кэш-памяти, результаты для компиляторов Intel и GNU практически совпадают.
Приведем аналогичное сравнение компиляторов на процессоре Pentium III/1 ГГц.
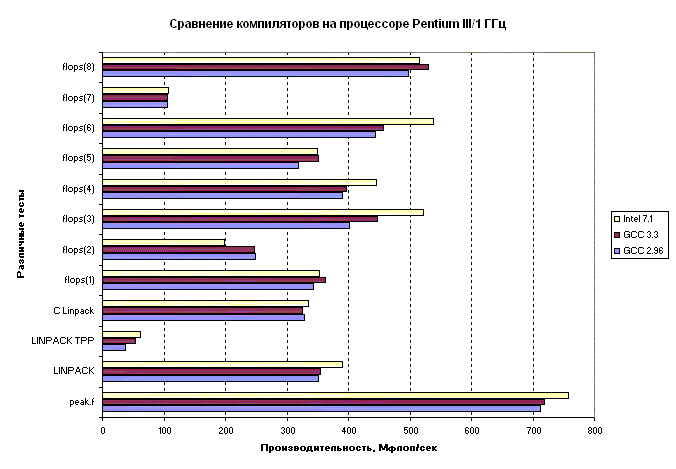
Производительность Pentium III/1ГГц при использовании компиляторов GNU и Intel.
В данном случае компиляторы Intel также несколько лучше, но не обеспечивают столь значительного выигрыша в производительности.
Насколько производительность Xeon лучше по сравнению с Pentium III?
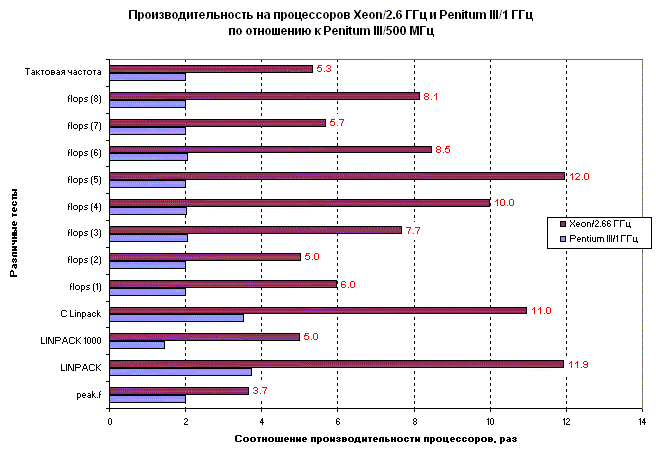
Производительность Xeon/2.6ГГц относительно Pentium III/1ГГц.
Здесь видно, что на большинстве тестов производительность улучшается примерно в 3 раза, что немного выше, чем увеличение тактовой частоты.
Производительность коммуникационной среды
Какие достигаются пиковые характеристики коммуникационной среды?
Латентность (время задержки сообщений) в рамках MPI поверх SCI составляет примерно 3.9 мксек. Скорость однонаправленных и пересылок составляет 250 Мбайт/сек.
Какие изменяются эти характеристики с изменением длины сообщения?
На следующем рисунке представлено результаты по времени передачи небольших сообщений (от 0 до 256 байт) на кластерах DWARF и SCI.
![]()
Время передачи
небольших сообщений в рамках MPI на кластерах DWARF и SCI.
На следующем рисунке представлена зависимость скорости однонаправленных пересылок от размера сообщения (от 1K до 16 Мбайт).
![]()
Скорость однонаправленных
пересылок в рамках MPI на кластерах DWARF и SCI.
Насколько эти характеристики лучше полученных ранее для других кластеров?
Из приведенных данных видно, что при больших размерах сообщений скорость пересылок на кластере DWARF примерно в 3 раза лучше по сравнению с кластером SCI и примерно в 25 раз лучше по сравнению с сетью Fast Ethernet (где достигаемая скорость пересылок составляет примерно 10 Мбайт/сек). Латентность (время пересылки сообщения нулевой длины) на кластере DWARF примерно в 1.5 раза лучше по сравнению с кластером SCI и примерно в 35 раз лучше по сравнению с сетью Fast Ethernet (где латентность составляет примерно 140 микросек).
Насколько можно ускорить обмен данными за счет использования двунаправленных пересылок?
![]()
Скорость однонаправленных
пересылок в рамках MPI на кластерах DWARF и SCI.
Какая достигается скорость обменов сообщениями на общей памяти?
![]()
Скорость однонаправленных
пересылок в рамках MPI внутри одного SMP-узла
на кластерах DWARF и SCI.
Здесь видно, что скорость обменов на общей памяти очень велика для сообщений среднего размера (от 8 до 64 Кбайт), что можно объяснить тем, что сообщения попадают в кэш-память. При увеличении размера сообщения до 256 Кбайт и выше скорость обменов на SMP-узле падает и стабилизируется на уровне примерно 310 Мбайт/сек.
Более подробную информацию об используемых здесь тестах производительности MPI можно найти по адресу http://parallel.ru/testmpi/.
Тест LINPACK
Тест LINPACK представляет собой решение больших систем линейных алгебраических уравнений методом LU-разложения. Результаты теста используются при составлении знаменитого списка Top500.
Производительность определяется как количество "содержательных" операций с плавающей точкой в расчете на 1 секунду, и выражается в MFLOPS. Число выполненных операций с плавающей точкой оценивается по формуле 2n3/3 + 2n2 (здесь n - размерность матрицы).
Была использована общедоступная параллельная реализация теста LINPACK - HPL, которая реализована на языке Си, причем обмены между процессорами выполняются через процедуры интерфейса MPI, а вычисления на каждом процессоре - с помощью вызовов процедур BLAS. В наших экспериментах на кластере DWARF в качестве BLAS использовалась библиотека ATLAS, откомпилированная нами с использованием компилятора GCC 3.3, а в качестве реализации MPI для сети SCI - библиотека ScaMPI компании Scali.
Какая достигается максимальная производительность всего кластера на LINPACK?
На кластере DWARF была получена максимальная производительность равная 61740 Мфлоп/сек (при решении задачи размером 35000x35000 на всех 24 процессорах). Это примерно в 9.5 раз лучше производительности, достигнутой на 24 процессорах старого кластера SCI и примерно в 19.5 раз лучше производительности на одном процессоре Xeon/2.6 МГц (на задаче размером 10000x10000).
Более подробные данные по производительности на LINPACK (с различным размером задачи, различным числом процессоров, при использовании 1 или 2 процессоров на узле, на разных кластерах, при использовании разных коммуникационных сред) будут приведены на следующих графиках и диаграммах.
Как изменяется производительность при увеличении размера задачи?
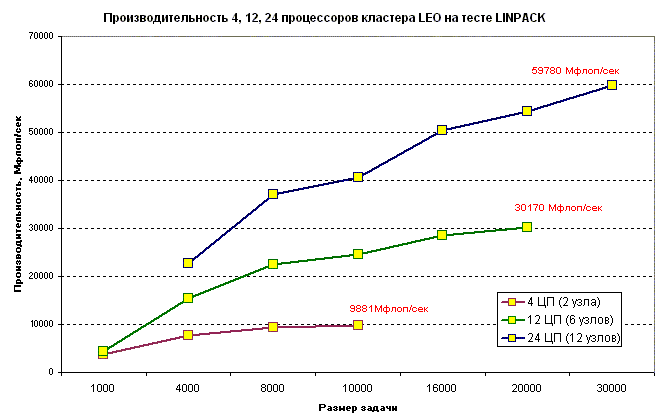
Производительность 4, 12, 24 процессоров на задаче LINPACK.
Из этого графика видно, что независимо от числа используемых процессоров производительность растет с ростом размера задачи до размера максимальной задачи, помещающейся в объем памяти доступных узлов. Это объясняется тем, что при увеличении размеров задачи уменьшается соотношение объема пересылок (т.е. накладных расходов) к объему собственно вычислений (объем пересылок растет линейным образом, а объем вычислений растет как N2).
Как увеличивается производительность с ростом числа процессоров?
Из предыдущего графика видно, что с увеличением числа используемых процессоров общая производительность почти всегда растет (за исключением задач очень малого размера, где возможна деградация производительности за счет накладных расходов). Другой вопрос - насколько хорошо растет эта производительность, иначе говоря, насколько оправдано использование большого числа процессоров для решения той или иной задачи? Чтобы это понять, приведем графики, где будет отражена производительность в расчете на 1 процессор. Будут приведены результаты экспериментов, когда на каждом двухпроцессорном вычислительном узле используется 1 или 2 процессора.
Чему равна производительность в расчете на 1 процессор?
Сначала приведем данные для задачи размером 10000x10000 (это максимальный размер, который попадает в память 1 узла).
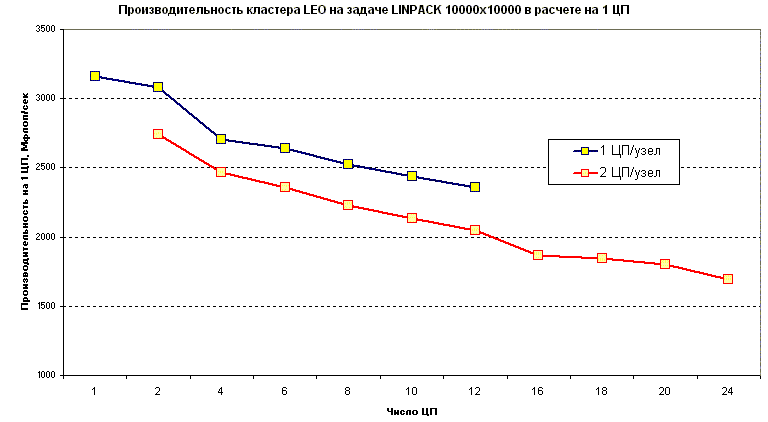
Из этого графика видно, что при фиксированном размере задачи производительность в расчете на 1 процессор равномерно падает c увеличением числа процессоров от 1 до 24 (примерно в 1.8 раза).
Как будет расти производительность, если вместе с количеством процессоров увеличивать размер задачи?
Поскольку с увеличением числа процессоров растет не только вычислительная мощность, но и объем оперативной памяти, то целесообразно оценивать производительность на задаче не фиксированного размера, а максимального размера, допустимого для данного числа процессоров.
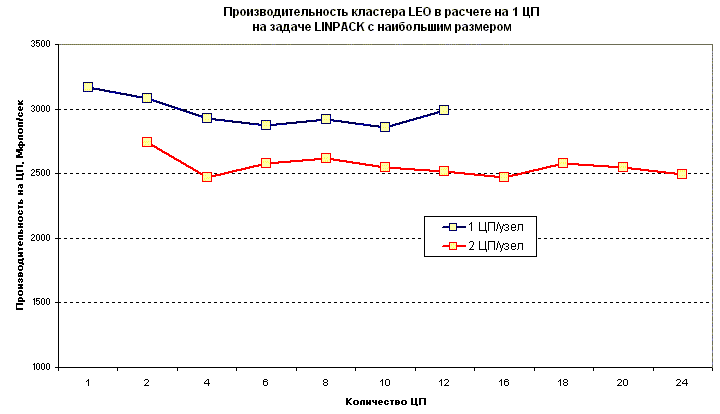
В этом случае производительность в расчете на 1 процессор остается почти постоянной величиной (около 3000 Мфлоп/сек и 2500 Мфлоп/сек при использовании соответственно 1 и 2 ЦП на узле), что является хорошей характеристикой для исследуемой конфигурации кластера.
Что дает использование двухпроцессорных узлов?
Из приведенных выше данных видно, что при фиксированном числе процессоров производительность почти всегда выше в случае использования только 1 процессора на узле. Таким образом, конфликты по памяти оказывают значительно отрицательное влияние на производительность, большее, чем влияние накладных расходов на пересылку данных между узлами с использованием сети SCI. Приведем и другие графики, которые это уточняют.
В следующих экспериментах одни и те же задача решались на 1 процессоре, на 2 процессора на одном узле (т.е. на общей памяти) и на разных узлах.
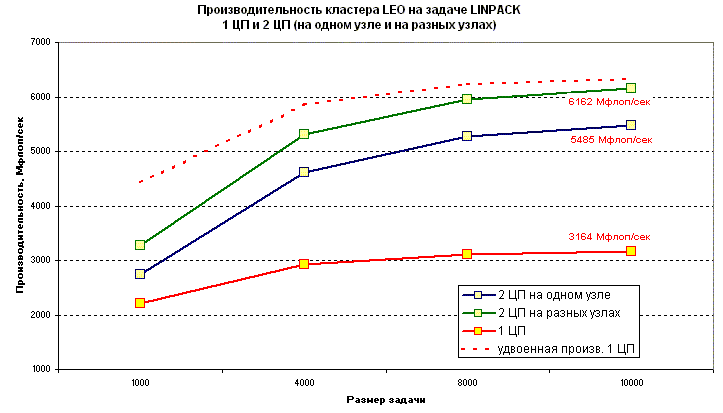
Здесь видно, что малых размерах задачи увеличение производительности за счет использования двух процессоров всегда очень мало. При большом размере задачи (10000x10000) использование 2 процессоров на разных узлах дает ускорение на 94%, а 2 процессоров на одном узле - только на 73%. Приведем данные по ускорению задачи фиксированного размера на большем числе процессоров.
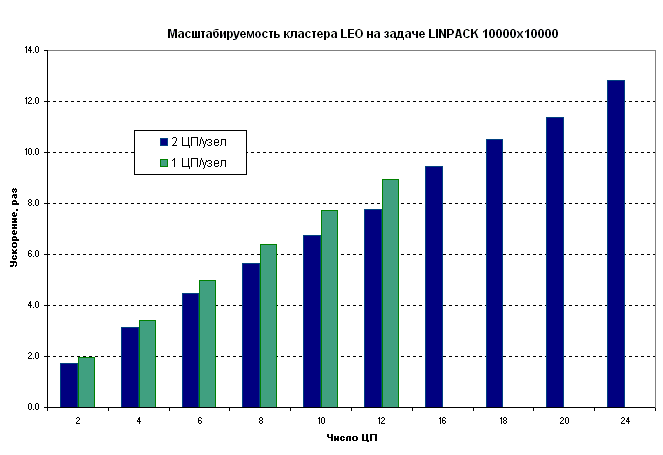
При использовании 12 процессоров на 12 различных узла, достигается ускорение в 8.9 раза по сравнению 1 процессором, а при 12 процессорах на 6 узлах - только в 7.8 раза.
Несмотря на то, что производительность почти всегда несколько хуже в случае 2 процессоров на каждом узле, считается, что использование двухпроцессорных узлов в высокопроизводительных кластерах оправданно по экономическим соображениям, т.к. в стоимость узла входит не только стоимость процессоров и оперативной памяти, но и других компонент, в частности, дорогостоящих коммуникационных адаптеров.
Что дает использование сети SCI по сравнению с Fast Ethernet?
Для сравнения на кластере DWARF был проведен ряд экспериментов с использованием сети 100 Мбит Ethernet (в этом случае в качестве реализации MPI использовался пакет MPICH). На задаче размером 10000x10000 при использовании 100-мегабитной сети на 24 процессорах удалось достигнуть производительности только в 8650 Мфлоп/сек, что примерно в 4.7 раза хуже, чем в случае с сетью SCI. Другие результаты этих экспериментов приведены на следующем графике:
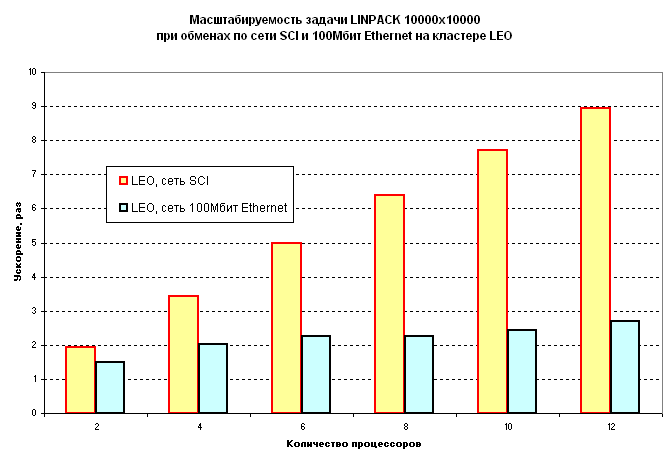
Здесь видно, при использовании 100-мегабитной сети на 12 процессорах не достигается и 3-кратного ускорения, и что использование вместо нее высокопроизводительной сети SCI дает значительный выигрыш в производительности даже при относительно небольшом числе процессоров. Такого эффекта не было заметно в конфигурациях с более медленными процессорами (см. результаты экспериментов на построенных ранее кластерах SCI и SKY). Из приведенных результатов также можно сделать вывод, что 100-мегабитную сеть имеет смысл использовать только для построения "вычислительных ферм", на которых будут запускаться 1-2-процессорные задачи.
Производительность на прикладных тестах
Какое ускорение достигается на прикладных задачах?
На кластерах SCI и DWARF был проведен ряд экспериментов с проведением расчетов (расчет энергии и градиента методом функционала плотности молекулы C60H60 из 120 атомов с 1860 базисными функциями) с помощью параллельной программы PRIRODA на различном числе процессоров (от 1 до 24). Результаты этих экспериментов представлены на следующем графике.
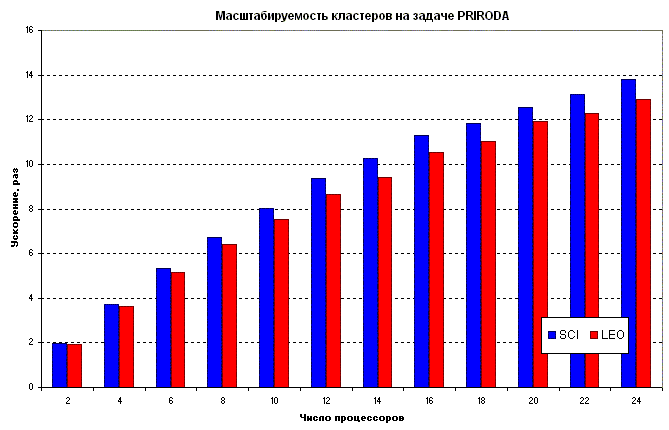
Здесь видно, что на 24 процессорах достигается ускорение примерно в 13 раз по сравнению с 1 процессором. Для кластера DWARF ускорение оказалось немного хуже по сравнению с кластером SCI, что вполне объяснимо - производительность процессоров на новом кластере увеличилась больше, чем производительность коммуникационной сети. По абсолютной величине производительность на кластере DWARF примерно в 5.5 раза выше по сравнению с кластером SCI, что соответствует увеличению тактовой частоты процессоров.
В целом эти результаты почти аналогичны результатам для теста LINPACK, что дает основание полагать, что LINPACK является вполне адекватным тестом для оценки вычислительной производительности и на некоторых реальных задачах (конечно, не на всех, т.к. есть задачи, которые гораздо сильнее загружают коммуникационную сеть).