Cluster OpenMP для компиляторов Intel под Linux
- Общая информация
- Использование OpenMP с раcпределенной общей памятью (DSM)
- Преимущества
- Системные требования
- Документация Intel
- Cluster OpenMP User Manual (полное руководство, включая опсиание опций и примеры) [PDF, eng., 574KB]
- Расширение OpenMP для кластерных систем [PDF, eng., 110KB]
- Тесты
Общая информация
Cluster OpenMP - простое средство, требующее незначительного изменения кода для расширения параллелелизма OpenMP на кластерные системы под ОС Linux, базирующиеся на 64-разрядной архитектуре Intel.
OpenMP - хорошо известная парадигма параллельного программирования для систем с общей памятью. Высокая стоимость больших систем с общей памятью была главным ограничением для использования OpenMP. Для совместного использования нескольких SMP-систем зачастую прибегали к помощи MPI для обмена сообщениями между этими системами. Разумеется, это неизбежно приводило к усложнению не только написания самой программы, но и к усложнению разработки приложения в целом, координации рабочих групп и т.п. Cluster OpenMP позволяет как избавиться от смешивания этих парадигм, так и сократить усилия на написание дополнительного кода. В в Cluster OpenMP поддерживается система распределенной общей памяти. Cluster OpenMP позволяет синхронизировать общие переменные только в случае необходимости.
На текущий момент Cluster OpenMP работает на системах под ОС Linux с поддержкой сокетов и uDAPL API на базе Intel Itanium и системах, поддерживающих Intel EM64T. Работоспособность проверена на Ethernet и Infiniband, однако, в будущем будет поддержка и других интерконнектов. Также планируется увеличение производительности за счет расширения использования новых возможностей таких средств, как RDMA.
Расширение Cluster OpenMP доступно для компиляторов Intel под Linux, начиная с версий 9.1. Использование Cluster OpenMP требует помимо собственной лицензию на использование компилятора Intel С++ или Fortran для Linux. Сама же лицензия на Cluster OpenMP может быть получена как отдельно, так и вместе с лицензией на компилятор.
Использование OpenMP с раcпределенной общей памятью (DSM)
Директива sharable
С введением механизма поддержки распределенной общей памяти в Cluster OpenMP появляется одна новая директива sharable. Она определяет переменные, на которые ссылаются несколько нитей, и доступ к которым должен обрабатываться как раз механизмом DSM. В очевидных случаях, например, когда под переменную в подпрограмме выделяется память, а далее она используется в параллельной части той же подпрограммы, компилятор сам помечает ее как sharable. Файловые переменные в С и С++ должны быть явно определены как sharable. Глобальные переменные в Fortran могут как быть определены sharable явно, так это может быть сделано и компилятором. Существуют опции компилятора, которые пометят все модульные переменные, COMMON, SAVE, как sharable. Существует и некоторая неоднозначность с вызовами по ссылке в Fortran. Если выражение используется как аргумент при вызове, при этом это значение используется далее в общей части где-то в графе вызовов, тогда его значение должно быть помечено как sharable. Это можно сделать и автоматически с помощью компилятора, однако, может получиться и так, что это будет сделано напрасно, т.к. реально переменная может оказаться невызванной в общей части.
В случае выделения памяти (malloc, calloc и т.д.) также следует учитывать, выделяется ли память для переменной sharable. В таком случае следует пользоваться соответствующими функциями (например, kmp_sharable_malloc вместо malloc).
Механизм DSM
Задача синхронизации переменных на разных узлах решается следующим образом. Разделяемые переменные группируются на определенных страницах памяти. Механизм опирается на защищенные страницы памяти с помощью системного вызова mprotect. Когда страница устаревает даже частично, она становится недоступной как для чтения, так и для записи. При запросе же возникает ошибка сегментации и инициируются запросы ко всем узлам, изменявшим значения в этой странице. Производится обновление, страница становится доступной на чтение, запрос, вызвавший это обновление, повторяется уже без ошибки. При попытке записи, аналогично, возникает ошибка. После этого создается копия, "twin", страницы, которая позволит отследить все вносимые изменения. Защита снимается, вносятся изменения. После создания такой копии все записи и чтения до следующей синхронизации происходят без ошибок, делая эти операции весьма "дешевыми". Т.е. локальная память на узле служит временной для каждой нити. При каждой операции синхронизации узлы получают информацию об измененных страницах на других узлах, делая уже такие операции чтения и записи "дорогими" до следующей синхронизации.
Все узлы делятся на основной (home), где была запущена программа и остальные. На каждом узле есть главная нить. Барьеры реализуются по двухуровневой схеме - сначала в рамках узла, далее - по самим узлам. Редукции выполняются как часть барьера и также выполняются в два этапа. Актуализация значений переменных происходит при барьерах, замках OpenMP, входах и выходах из критических и атомарных секций. Уведомления о записи от всех нитей отправляются всем другим нитям при барьерах. Они также посылаются от ждущего узла узлу, которого он ждет.
Исходя из вышесказанного, очевидно, что, при разработке программы следует строить ее так, чтобы максимизировать число обращений к локальной памяти между барьерами и уменьшать общее число синхронизаций. Следует также помнить, что последовательность чтений и записей переменных в Cluster OpenMP унаследована из OpenMP, т.е. до специального указания (flush), вообще говоря, последовательность этих операций неоднозначна.
Соответственно, и наиболее подходящий класс приложений для Cluster OpenMP - задачи поиска, синтеза и подобной однородной обработки больших порций данных, которые могут быть распределены по узлам, минимизируя взаимодействие различных узлов.
Преимущества Cluster OpenMP
Переносимость и гибкость упрощает и снижает стоимость разработки приложений:
- Упрощает распределение последовательного или OpenMP кода по узлам.
- Позволяет использовать один и тот же код приложений для последовательных, многоядерных и кластерных систем.
- Требует совсем незначительного изменения кода, что упрощает отладку.
- Позволяет слегка измененному коду OpenMP выполняться на большем числе процессоров без вложений в аппаратную составляющую SMP.
- Представляет собой альтернативу MPI, которая может быть быстрее освоена и применена.
Стоимость вычислений на кластерных системах:
| Тип кластера | Аппаратная составляющая расходов |
Программная составляющая расходов |
|---|---|---|
| Большие SMP системы с общей памятью и OpenMP |  |
 |
| Кластерные системы с распределенной памятью и MPI | |
|
| Кластерные системы с распределенной памятью и Cluster OpenMP | |
|
Типы задач, когда использование Cluster OpenMP наиболее целесообразно
- Обработка больших массивов данных
- Рендеринг в графике
- Поиск
- Распознавание образов
- Выделение последовательностей в генетике
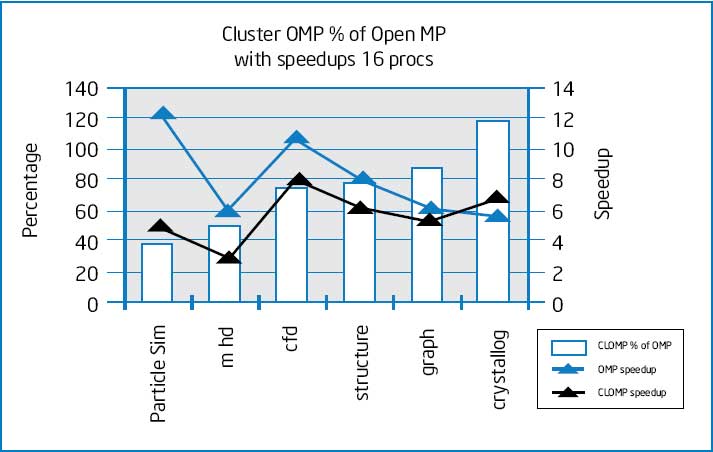
Тесты
Тест Intel
Тесты проводились на двух системах: OpenMP на 32-процессорной системе с Itanium-2 и Cluster OpenMP на кластере на базе Itanium-2. Частота процессоров 1.5ГГц, кэш L3 6Mb.
© Лаборатория Параллельных
информационных технологий НИВЦ МГУ