© Крюков В.А.
Курс лекций
"Распределенные ОС"
5. Распределенные файловые системы
Две главные цели.Сетевая прозрачность.
Самая важная цель - обеспечить те же самые возможности доступа к файлам,
распределенным по сети ЭВМ, которые обеспечиваются в системах разделения
времени на централизованных ЭВМ.
Высокая доступность.
Другая важная цель - обеспечение высокой доступности. Ошибки систем
или осуществление операций копирования и сопровождения не должны приводить
к недоступности файлов.
Понятие файлового сервиса и файлового сервера.
Файловый сервис - это то, что файловая система предоставляет
своим клиентам, т.е. интерфейс с файловой системой.
Файловый сервер - это процесс, который реализует файловый сервис.
Пользователь не должен знать, сколько файловых серверов имеется и где они расположены.
Так, как файловый сервер обычно является обычным пользовательским процессом, то в системе могут быть различные файловые серверы, предоставляющие различный сервис (например, UNIX файл сервис и MS-DOS файл сервис).
5.1 Архитектура распределенных файловых систем
Распределенная система обычно имеет два существенно отличающихся компонента - непосредственно файловый сервис и сервис директорий.
5.1.1 Интерфейс файлового сервера
Для любой файловой системы первый фундаментальный вопрос - что такое файл. Во многих системах, таких как UNIX и MS-DOS, файл - не интерпретируемая последовательность байтов. На многих централизованных ЭВМ (IBM/370) файл представляется последовательность записей, которую можно специфицировать ее номером или содержимым некоторого поля (ключом). Так, как большинство распределенных систем базируются на использовании среды UNIX и MS-DOS, то они используют первый вариант понятия файла.
Файл может иметь атрибуты (информация о файле, не являющаяся его частью). Типичные атрибуты - владелец, размер, дата создания и права доступа.
Важный аспект файловой модели - могут ли файлы модифицироваться после создания. Обычно могут, но есть системы с неизменяемыми файлами. Такие файлы освобождают разработчиков от многих проблем при кэшировании и размножении.
Защита обеспечивается теми же механизмами, что и в однопроцессорных ЭВМ - мандатами и списками прав доступа. Мандат - своего рода билет, выданный пользователю для каждого файла с указанием прав доступа. Список прав доступа задает для каждого файла список пользователей с их правами. Простейшая схема с правами доступа - UNIX схема, в которой различают три типа доступа (чтение, запись, выполнение), и три типа пользователей (владелец, члены его группы, и прочие).
Файловый сервис может базироваться на одной из двух моделей - модели загрузки/разгрузки и модели удаленного доступа. В первом случае файл передается между клиентом (памятью или дисками) и сервером целиком, а во втором файл сервис обеспечивает множество операций (открытие, закрытие, чтение и запись части файла, сдвиг указателя, проверку и изменение атрибутов, и т.п.). Первый подход требует большого объема памяти у клиента, затрат на перемещение ненужных частей файла. При втором подходе файловая система функционирует на сервере, клиент может не иметь дисков и большого объема памяти.
5.1.2 Интерфейс сервера директорий
Обеспечивает операции создания и удаления директорий, именования и переименования файлов, перемещение файлов из одной директории в другую.
Определяет алфавит и синтаксис имен. Для спецификации типа информации в файле используется часть имени (расширение) либо явный атрибут.
Все распределенные системы позволяют директориям содержать поддиректории - такая файловая система называется иерархической. Некоторые системы позволяют создавать указатели или ссылки на произвольные директории, которые можно помещать в директорию. При этом можно строить не только деревья, но и произвольные графы (разница между ними очень важна для распределенных систем, поскольку в случае графа удаление связи может привести к появлению недостижимых поддеревьев. Обнаруживать такие поддеревья в распределенных системах очень трудно).
Ключевое решение при конструировании распределенной файловой системы - должны или не должны машины (или процессы) одинаково видеть иерархию директорий. Тесно связано с этим решением наличие единой корневой директории (можно иметь такую директорию с поддиректориями для каждого сервера).
Прозрачность именования.
Две формы прозрачности именования различают - прозрачность расположения
(/server/d1/f1) и прозрачность миграции (когда изменение расположения файла
не требует изменения имени).
- машина + путь;
- монтирование удаленных файловых систем в локальную иерархию файлов;
- единственное пространство имен, которое выглядит одинаково на всех машинах.
Имеются три подхода к именованию:
Двухуровневое именование.
Большинство систем используют ту или иную форму двухуровневого именования. Файлы (и другие объекты) имеют символические имена для пользователей, но могут также иметь внутренние двоичные имена для использования самой системой. Например, в операции открыть файл пользователь задает символическое имя, а в ответ получает двоичное имя, которое и использует во всех других операциях с данным файлом.
- если имеется несколько не ссылающихся друг на друга серверов (директории не содержат ссылок на объекты других серверов), то двоичное имя может быть то же самое, что и в ОС UNIX;
- имя может указывать на сервер и файл;
- в качестве двоичных имен при просмотре символьных имен возвращаются мандаты, содержащие помимо прав доступа либо физический номер машины с сервером, либо сетевой адрес сервера, а также номер файла.
5.1.3 Семантика разделения файлов
UNIX-семантика
Естественная семантика однопроцессорной ЭВМ - если за операцией записи
следует чтение, то результат определяется последней из предшествующих операций
записи. В распределенной системе такой семантики достичь легко только в
том случае, когда имеется один файл-сервер, а клиенты не имеют кэшей. При
наличии кэшей семантика нарушается. Надо либо сразу все изменения в кэшах
отражать в файлах, либо менять семантику разделения файлов.
Еще одна проблема - трудно сохранить семантику общего указателя файла (в UNIX он общий для открывшего файл процесса и его дочерних процессов) - для процессов на разных ЭВМ трудно иметь общий указатель.
Неизменяемые файлы - очень радикальный подход к изменению
семантики разделения файлов.
Только две операции - создать и читать. Можно заменить новым файлом
старый - т.е. можно менять директории. Если один процесс читает файл, а
другой его подменяет, то можно позволить первому процессу доработать со
старым файлом в то время, как другие процессы могут уже работать с новым.
Транзакции
Процесс выдает операцию НАЧАЛО ТРАНЗАКЦИИ, сообщая тем самым, что последующие
операции должны выполняться без вмешательства других процессов. Затем выдает
последовательность чтений и записей, заканчивающуюся операцией КОНЕЦ ТРАНЗАКЦИИ.
Если несколько транзакций стартуют в одно и то же время, то система гарантирует,
что результат будет таким, каким бы он был в случае последовательного выполнения
транзакций (в неопределенном порядке). Пример - банковские операции.
5.2 Реализация распределенных файловых систем
Выше были рассмотрены аспекты распределенных файловых систем, которые видны пользователю. Ниже рассматриваются реализационные аспекты.
5.2.1 Использование файлов
Приступая к реализации очень важно понимать, как система будет использоваться. Приведем результаты некоторых исследований использования файлов (статических и динамических) в университетах. Очень важно оценивать представительность исследуемых данных.
- большинство файлов имеют размер менее 10К (следует перекачивать целиком).
- чтение встречается гораздо чаще записи (кэширование).
- чтение и запись последовательны, произвольный доступ редок (упреждающее кэширование, чтение с запасом, выталкивание после записи следует группировать).
- большинство файлов имеют короткое время жизни (создавать файл в клиенте и держать его там до уничтожения).
- мало файлов разделяются (кэширование в клиенте и семантика сессий).
- существуют различные классы файлов с разными свойствами (следует иметь в системе разные механизмы для разных классов).
5.2.2 Структура системы
Есть ли разница между клиентами и серверами? Имеются системы, где все машины имеют одно и то же ПО и любая машина может предоставлять файловый сервис. Есть системы, в которых серверы являются обычными пользовательскими процессами и могут быть сконфигурированы для работы на одной машине с клиентами или на разных. Есть системы, в которых клиенты и серверы являются фундаментально разными машинами с точки зрения аппаратуры или ПО (требуют различных ОС, например).
Второй вопрос - должны ли быть файловый сервер и сервер директорий отдельными серверами или быть объединенными в один сервер. Разделение позволяет иметь разные серверы директорий (UNIX, MS-DOS) и один файловый сервер. Объединение позволяет сократить коммуникационные издержки.
В случае разделения серверов и при наличии разных серверов директорий для различных поддеревьев возникает следующая проблема. Если первый вызванный сервер будет поочередно обращаться ко всем следующим, то возникают большие коммуникационные расходы. Если же первый сервер передает остаток имени второму, а тот третьему, и т.д., то это не позволяет использовать RPC.
Возможный выход - использование кэша подсказок. Однако в этом случае при получении от сервера директорий устаревшего двоичного имени клиент должен быть готов получить отказ от файлового сервера и повторно обращаться к серверу директорий (клиент может не быть конечным пользователем!).
Последний важный вопрос - должны ли серверы хранить информацию о клиентах.
Серверы с состоянием. Достоинства.
- Короче сообщения (двоичные имена используют таблицу открытых файлов).
- выше эффективность (информация об открытых файлах может храниться в оперативной памяти).
- блоки информации могут читаться с упреждением.
- убедиться в достоверности запроса легче, если есть состояние (например, хранить номер последнего запроса).
- возможна операция захвата файла.
Серверы без состояния. Достоинства.
- устойчивость к ошибкам.
- не требуется операций ОТКРЫТЬ/ЗАКРЫТЬ.
- не требуется память для таблиц.
- нет ограничений на число открытых файлов.
- нет проблем при крахе клиента.
5.2.3 Кэширование
В системе клиент-сервер с памятью и дисками есть четыре потенциальных места для хранения файлов или их частей.Во-первых, хранение файлов на дисках сервера. Нет проблемы когерентности, так как одна копия файла существует. Главная проблема - эффективность, поскольку для обмена с файлом требуется передача информации в обе стороны и обмен с диском.
Кэширование в памяти сервера. Две проблемы - помещать в кэш файлы целиком или блоки диска, и как осуществлять выталкивание из кэша.
Коммуникационные издержки остаются.
Избавиться от коммуникаций позволяет кэширование в машине клиента.
Кэширование на диске клиента может не дать преимуществ перед кэшированием в памяти сервера, а сложность повышается значительно.
Поэтому рассмотрим подробнее организацию кэширования в памяти клиента.
- кэширование в каждом процессе. (Хорошо, если c файлом активно работает один процесс - многократно открывает и закрывает файл, читает и пишет, например в случае процесса базы данных).
- кэширование в ядре. (Накладные расходы на обращение к ядру).
- кэш-менеджер в виде отдельного процесса. (Ядро освобождается от функций файловой системы, но на пользовательском уровне трудно эффективно использовать память, особенно в случае виртуальной памяти. Возможна фиксация страниц, чтобы избежать обменов с диском).
- Когерентность кэшей.
Необходимость проверки, не устарела ли информация в кэше. Запись вызывает коммуникационные расходы (MS-DOS).
Алгоритм с отложенной записью.
Через регулярные промежутки времени все модифицированные блоки пишутся
в файл. Эффективность выше, но семантика непонятная пользователю (UNIX).
Алгоритм записи в файл при закрытии файла.
Реализует семантику сессий. Не намного хуже случая, когда два процесса
на одной ЭВМ открывают файл, читают его, модифицируют в своей памяти и
пишут назад в файл.
Алгоритм централизованного управления.
Можно выдержать семантику UNIX, но не эффективно, ненадежно, и плохо
масштабируется.
5.2.4 Размножение
Система может предоставлять такой сервис, как поддержание для указанных файлов нескольких копий на различных серверах. Главные цели:- Повысить надежность.
- Повысить доступность (крах одного сервера не вызывает недоступность размноженных файлов.
- Распределить нагрузку на несколько серверов.
- Явное размножение (непрозрачно). В ответ на открытие файла пользователю выдаются несколько двоичных имен, которые он должен использовать для явного дублирования операций с файлами.
- Ленивое размножение. Одна копия создается на одном сервере, а затем он сам автоматически создает (в свободное время) дополнительные копии и обеспечивает их поддержание.
- Симметричное размножение. Все операции одновременно вызываются в нескольких серверах и одновременно выполняются.
Просто посылка сообщений с операцией коррекции каждой копии является не очень хорошим решением, поскольку в случае аварий некоторые копии могут остаться не скорректированными. Имеются два алгоритма, которые решают эту проблему.
- Метод размножения главной копии. Один сервер объявляется главным, а остальные - подчиненными. Все изменения файла посылаются главному серверу. Он сначала корректирует свою локальную копию, а затем рассылает подчиненным серверам указания о коррекции. Чтение файла может выполнять любой сервер. Для защиты от краха главного сервера до завершения всех коррекций, до выполнения коррекции главной копии главный сервер запоминает в стабильной памяти задание на коррекцию. Слабость - выход из строя главного сервера не позволяет выполнять коррекции.
- Метод голосования. Идея - запрашивать чтение и запись файла у многих серверов (запись - у всех!). Запрос может получить одобрение у половины серверов плюс один. При этом должно быть согласие относительно номера текущей версии файла. Этот номер увеличивается на единицу с каждой коррекцией файла. Можно использовать различные значения для кворума чтения (Nr) и кворума записи (Nw). При этом должно выполняться соотношение Nr+Nw>N. Поскольку чтение является более частой операцией, то естественно взять Nr=1. Однако в этом случае для кворума записи потребуются все серверы.
5.2.5 Пример: Sun Microsystems Network File System (NFS)
Изначально реализована Sun Microsystem в 1985 году для использования на своих рабочих станций на базе UNIX. В настоящее время поддерживается также другими фирмами для UNIX и других ОС (включая MS-DOS). Интересны следующие аспекты NFS - архитектура, протоколы и реализация.Каждый сервер экспортирует некоторое число своих директорий для доступа к ним удаленных клиентов. При этом экспортируются директории со всеми своими поддиректориями, т.е. фактически поддеревья. Список экспортируемых директорий хранится в специальном файле, что позволяет при загрузке сервера автоматически их экспортировать.
Клиент получает доступ к экспортированным директориям путем их монтирования. Если клиент не имеет дисков, то может монтировать директории в свою корневую директорию.
Если несколько клиентов одновременно смонтировали одну и ту же директорию, то они могут разделять файлы в общей директории без каких либо дополнительных усилий. Простота - достоинство NFS.
Первый протокол поддерживает монтирование. Клиент может послать серверу составное имя директории (имя пути) и попросить разрешения на ее монтирование. Куда будет монтировать директорию клиент для сервера значения не имеет и поэтому не сообщается ему. Если путь задан корректно и директория определена как экпортируемая, то сервер возвращает клиенту дескриптор директории. Дескриптор содержит поля, уникально идентифицирующие тип ЭВМ, диск, номер i-вершины (понятие ОС UNIX) для данной директории, а также информацию о правах доступа к ней. Этот дескриптор используется клиентом в последующих операциях с директорией.
Многие клиенты монтируют требуемые удаленные директории автоматически при запуске (используя командную процедуру shell-интерпретатора ОС UNIX).
Версия ОС UNIX, разработанная Sun (Solaris), имеет свой специальный режим автоматического монтирования. С каждой локальной директорией можно связать множество удаленных директорий. Когда открывается файл, отсутствующий в локальной директории, ОС посылает запросы всем серверам (владеющим указанными директориями). Кто ответит первым, директория того и будет смонтирована. Такой подход обеспечивает и надежность, и эффективность (кто свободнее, тот раньше и ответит). При этом подразумевается, что все альтернативные директории идентичны. Поскольку NFS не поддерживает размножение файлов или директорий, то такой режим автоматического монтирования в основном используется для директорий с кодами программ или других редко изменяемых файлов.
Второй протокол - для доступа к директориям и файлам. Клиенты посылают сообщения, чтобы манипулировать директориями, читать и писать файлы. Можно получить атрибуты файла. Поддерживается большинство системных вызовов ОС UNIX, исключая OPEN и CLOSE. Для получения дескриптора файла по его символическому имени используется операция LOOKUP, отличающаяся от открытия файла тем, что никаких внутренних таблиц не создается. Таким образом, серверы в NFS не имеют состояния (stateless). Поэтому для захвата файла используется специальный механизм.
NFS использует механизм защиты UNIX. В первых версиях все запросы содержали идентификатор пользователя и его группы (для проверки прав доступа). Несколько лет эксплуатации системы показали слабость такого подхода. Теперь используется криптографический механизм с открытыми ключами для проверки законности каждого запроса и ответа. Данные не шифруются.
Все ключи, используемые для контроля доступа, поддерживаются специальным сервисом (и серверами) - сетевым информационным сервисом (NIS). Храня пары (ключ, значение), сервис обеспечивает выдачу значения кода при правильном подтверждении ключей. Кроме того, он обеспечивает отображение имен машин на их сетевые адреса, и другие отображения. NIS-серверы используют схему главный -подчиненные для реализации размножения (ленивое размножение).
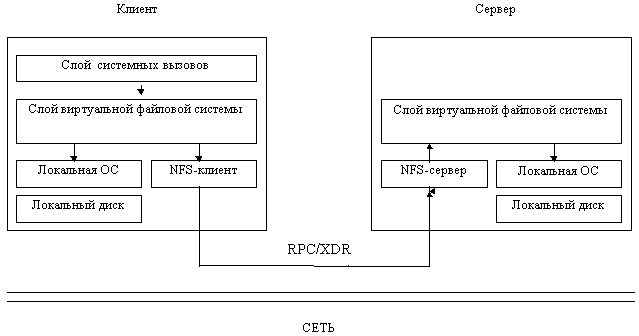
Задача уровня виртуальной файловой системы - поддерживать для каждого открытого файла строку в таблице (v-вершину), аналогичную i-вершине UNIX. Эта строка позволяет различать локальные файлы от удаленных. Для удаленных файлов вся необходимая информация хранится в специальной r-вершине в NFS-клиенте, на которую ссылается v-вершина. У сервера нет никаких таблиц.
Передачи информации между клиентом и сервером NFS производятся блоками размером 8К (для эффективности).
Два кэша - кэш данных и кэш атрибутов файлов (обращения к ним очень часты, разработчики NFS исходили из оценки 90%). Реализована семантика отложенной записи - предмет критики NFS.
Имеется также кэш подсказок для ускорения получения v-вершины по символическому имени. При использовании устаревшей подсказки NFS-клиент будет обращаться к NFS-серверу и корректировать свой кэш (пользователь об этом ничего не должен знать).
|
|
|
© Лаборатория Параллельных Информационных Технологий, НИВЦ МГУ