Архитектура ГПУ от NVIDIA
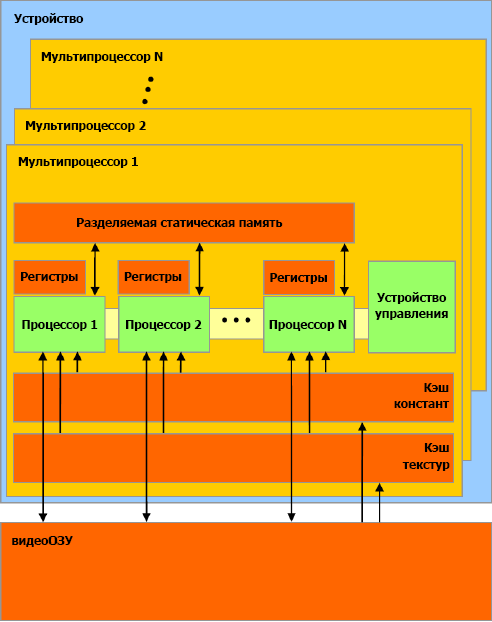
Архитектура ГПУ семейства NVidia GeForce 8.
Архитектура ГПУ семейства NVidia GeForce 8 не является классическим представителем класса SIMD: 128 ПП объединены в SIMD-группы по 16 мультипроцессоров (МП), но при этом разные МП работают независимо друг от друга, хотя и исполняют один и тот же шейдер.
Каждый ПП является суперскалярным устройством и может выполнять до 2 команд за такт. При обращении в видеоОЗУ ему доступна вся память, как на чтение, так и на запись. Однако на практике, ввиду слабости средств синхронизации между различными МП, желательно процесс обработки строить так, чтобы адреса записи не пересекались.
В GeForce 8 программисту доступны 16 КБ явно адресуемой статической памяти на МП. Она используется совместно всеми ПП одного мультипроцессора, внутри которого существует механизм барьерной синхронизации потоков. Грамотное использование статической памяти является ключом к написанию эффективных программ для данной архитектуры.
Серия ГПУ, ориентированная на высокопроизводительные вычисления, носит название Tesla.
© Лаборатория Параллельных информационных технологий НИВЦ МГУ