Классификация Базу
По мнению А.Базу (A.Basu), любую параллельную вычислительную систему можно однозначно описать последовательностью решений, принятых на этапе ее проектирования, а сам процесс проектирования представить в виде дерева [18]. В самом деле, корень дерева - это вычислительная система (см. рисунок), а последующие ярусы дерева, фиксируя уровень параллелизма, метод реализации алгоритма, параллелизм инструкций и способ управления, последовательно дополняют друг друга, формируя описание системы.
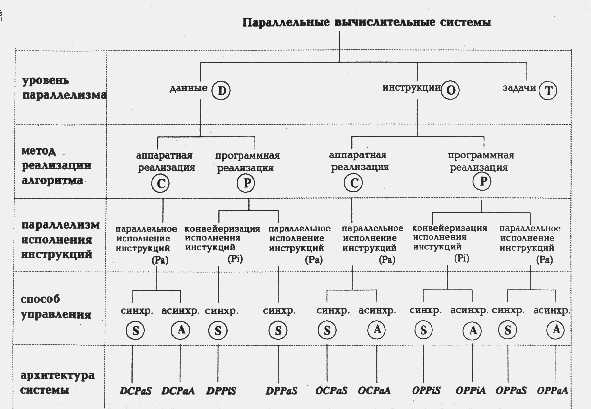
На первом этапе мы определяем, какой уровень параллелизма используется в вычислительной системе. Одна и та же операция может одновременно выполняться над целым набором данных, определяя параллелизм на уровне данных (обозначается буквой D на рисунке). Способность выполнять более одной операции одновременно говорит о параллелизме на уровне команд (буква O на рисунке). Если же компьютер спроектирован так, что целые последовательности команд могут быть выполнены одновременно, то будем говорить о параллелизме на уровне задач (буква T).
Второй уровень в классификационном дереве фиксирует метод реализации алгоритма. С появлением сверхбольших интегральных схем (СБИС) стало возможным реализовывать аппаратно не только простые арифметические операции, но и алгоритмы целиком. Например, быстрое преобразование Фурье, произведение матриц и LU-разложение относятся к классу тех алгоритмов, которые могут быть эффективно реализованы в СБИС'ах. Данный уровень классификации разделяет системы с аппаратной реализацией алгоритмов (буква C на схеме) и системы, использующие традиционный способ программной реализации (буква P).
Третий уровень конкретизирует тип параллелизма, используемого для обработки инструкций машины: конвейеризация инструкций (Pi) или их независимое (параллельное) выполнение (Pa). В большей степени этот выбор относится к компьютерам с программной реализацией алгоритмов, так как аппаратная реализация всегда предполагает параллельное исполнение команд. Отметим, что в случае конвейерного исполнения имеется в виду лишь конвейеризация самих команд, разбивающая весь цикл обработки на выборку команды, дешифрацию, вычисление адресов и т.д., - возможная конвейеризация вычислений на данном уровне не принимается во внимание.
Последний уровень данной классификации определяет способ управления, принятый в вычислительной системе: синхронный (S) или асинхронный (A). Если выполнение команд происходит в строгом порядке, определяемом только сигналами таймера и счетчиком команд, то будем говорить о синхронном способе управления. Если же для инициации команды определяющими являются такие факторы, как, например, готовность данных, то попадаем в класс машин с асинхронным управлением. Наиболее характерными представителями систем с асинхронным управлением являются data-driven и demand-driven компьютеры
Описав основные принципы классификации, посмотрим, куда попадают различные типы параллельных вычислительных систем.
Изучение систолических массивов, имеющих, как правило, одномерную или двумерную структуру, показывает, что обозначения DCPaS и DCPaA могут быть использованы для их описания в зависимости от того, как происходит обмен данными: синхронно или асинхронно. Систолические деревья, введенные Кунгом для вычисления арифметических выражений могут быть описаны как OCPaS либо OCPaA по аналогичным соображениям. Конвейерные компьютеры, такие, как IBM 360/91, Amdahl 470/6 и многие современные RISC процессоры, разбивающие исполнение всех инструкций на несколько этапов, в данной классификации имеют обозначение OPPiS. Более естественное применение конвейеризации происходит в векторных машинах, в которых одна команда применяется к вектору независимых данных, и за счет непрерывного использования арифметического конвейера достигается значительное ускорение. К таким компьютерам подходит обозначение DPPiS. Матричные процессоры, в которых целое множество арифметических устройств работает одновременно в строго синхронном режиме, принадлежат к группе DPPaS. Если вычислительная система подобно CDC 6600 имеет процессор с отдельными функциональными устройствами, управляемыми централизованно, то ее описание выглядит так: OPPaS. Data-flow компьютеры, в зависимости от особенностей реализации, могут быть описаны либо как OPPiA, либо OPPaA.
Системы с несколькими процессорами, использующими параллелизм на уровне задач, не всегда можно корректно описать в рамках предложенного формализма. Если процессоры дополнительно не используют параллелизм на уровне операций или данных, то для описания можно использовать лишь букву T. В противном случае, Базу предлагает использовать знак '*' между символами, обозначающими уровни параллелизма, одновременно присутствующие в системе. Например, комбинация T*D означает, что некоторая система может одновременно исполнять несколько задач, причем каждая из них может использовать векторные команды.
Очень часто в реальных системах присутствуют особенности, характерные для компьютеров из разных групп данной классификации. В этом случае для корректного описания автор использует знак '+'. Например, практически все векторные компьютеры имеют скалярную и векторную части, что можно описать как OPPiS+DPPiS (пример - это TI ASC и CDC STAR-100). Если в системе есть возможность одновременного выполнения более одной векторной команды (как в CRAY-1) то для описания векторной части можно использовать запись O*DPPiS, а полное описание данного компьютера выглядит так: O*DPPiS+OPPiS. Действуя по такому же принципу, можно найти описание и для систем CRAY X-MP и CRAY Y-MP. В самом деле, данные системы объединяют несколько процессоров, имеющих схожую с CRAY-1 структуру, и потому их описание имеет вид: T*(O*DPPiS+OPPiS).
© Лаборатория Параллельных информационных технологий НИВЦ МГУ